SciPy 中的通用非均匀随机数采样#
SciPy 提供了许多通用非均匀随机数生成器的接口,用于从各种单变量连续和离散分布中采样随机变量。为了提高速度和性能,使用了名为 UNU.RAN 的快速 C 库的实现。请参阅 UNU.RAN 的文档,以深入了解这些方法。本文档和所有生成器的文档都大量参考了该文档。
引言#
随机变量生成是研究从各种分布中生成随机变量算法的小领域。通常假设存在一个均匀随机数生成器。这是一个程序,它产生一系列独立同分布的连续 U(0,1) 随机变量(即在区间 (0,1) 上均匀分布的随机变量)。当然,现实世界的计算机永远无法生成理想的随机数,也无法生成任意精度的数字,但最先进的均匀随机数生成器已接近此目标。因此,随机变量生成解决了将 U(0,1) 随机数序列转换为非均匀随机变量的问题。这些方法是通用的,并且以黑盒方式工作。
一些实现方法包括
逆变换方法:当累积分布函数的逆 \(F^{-1}\) 已知时,随机变量生成就很简单。我们只需生成一个均匀分布在 U(0,1) 上的随机数 U,然后返回 \(X = F^{-1}(U)\)。由于逆函数的封闭形式解很少可用,通常需要依赖逆函数的近似值(例如
scipy.special.ndtri、scipy.special.stdtrit)。一般来说,与 UNU.RAN 中的逆变换方法相比,特殊函数的实现相当慢。拒绝采样方法:拒绝采样方法,通常称为接受-拒绝方法,由约翰·冯·诺依曼于 1951 年提出[1]。它涉及计算 PDF 的上限(也称为“帽函数”),并使用逆变换方法从该上限生成一个随机变量,例如 Y。然后可以在 0 到上限在 Y 处的值之间抽取一个均匀随机数。如果此数小于 PDF 在 Y 处的值,则返回样本,否则拒绝。参见
scipy.stats.sampling.TransformedDensityRejection。均匀比方法:这是一种接受-拒绝方法,它使用最小边界矩形来构建帽函数。参见
scipy.stats.sampling.RatioUniforms。离散分布的逆变换:与连续情况的区别在于 \(F\) 现在是一个阶梯函数。为了在计算机中实现这一点,使用了一种搜索算法,其中最简单的是 顺序搜索。生成一个 U(0, 1) 的均匀随机数,然后累加概率,直到累积概率超过该均匀随机数。发生这种情况的索引就是所需的随机变量并被返回。
这些算法的更多详细信息可以在 UNU.RAN 用户手册的附录中找到。
生成分布的随机变量时,有两个因素对于确定生成器的速度很重要:设置步骤和实际采样。根据情况,不同的生成器可能是最佳的。例如,如果需要从具有固定形状参数的给定分布中重复抽取大量样本,则如果采样速度快,慢速设置也是可以接受的。这称为固定参数情况。如果目的是为不同形状参数(变化参数情况)的分布生成样本,则需要为每个参数重复的昂贵设置将导致非常差的性能。在这种情况下,快速设置对于实现良好性能至关重要。下表显示了不同方法的设置和采样速度概述。
连续分布的方法 |
必要输入 |
可选输入 |
设置速度 |
采样速度 |
|---|---|---|---|---|
pdf, dpdf |
无 |
慢 |
快 |
|
cdf |
pdf, dpdf |
(很)慢 |
(很)快 |
|
cdf |
(很)慢 |
(很)快 |
||
无 |
快 |
慢 |
其中
pdf: 概率密度函数
dpdf: pdf 的导数
cdf: 累积分布函数
为了以最小的努力将数值逆变换方法 NumericalInversePolynomial 应用于 SciPy 中的大量连续分布,请参阅 scipy.stats.sampling.FastGeneratorInversion。
离散分布的方法 |
必要输入 |
可选输入 |
设置速度 |
采样速度 |
|---|---|---|---|---|
pv |
pmf |
慢 |
非常快 |
|
pv |
pmf |
慢 |
非常快 |
其中
pv: 概率向量
pmf: 概率质量函数
接口的基本概念#
每个生成器在使用前都需要进行设置。这可以通过实例化该类的一个对象来完成。大多数生成器都接受一个分布对象作为输入,该对象包含所需方法(如 PDF、CDF 等)的实现。除了分布对象之外,还可以传递用于设置生成器的参数。还可以使用 `domain` 参数截断分布。所有生成器都需要一个均匀随机数流,这些数被转换为给定分布的随机变量。这通过传递一个 `random_state` 参数完成,该参数包含一个 NumPy BitGenerator 作为均匀随机数生成器。`random_state` 可以是整数、numpy.random.Generator 或 numpy.random.RandomState。
警告
不建议使用 NumPy < 1.19.0,因为它没有用于生成均匀随机数的快速 Cython API,并且可能对于实际使用来说太慢。
所有生成器都有一个共同的 `rvs` 方法,可用于从给定分布中抽取样本。
下面是该接口的一个示例
from scipy.stats.sampling import TransformedDensityRejection
from math import exp
import numpy as np
class StandardNormal:
def pdf(self, x: float) -> float:
# note that the normalization constant isn't required
return exp(-0.5 * x*x)
def dpdf(self, x: float) -> float:
return -x * exp(-0.5 * x*x)
dist = StandardNormal()
urng = np.random.default_rng()
rng = TransformedDensityRejection(dist, random_state=urng)
如示例所示,我们首先初始化一个分布对象,其中包含生成器所需方法的实现。在我们的例子中,我们使用 TransformedDensityRejection (TDR) 方法,该方法需要 PDF 及其关于 `x`(即变量)的导数。
注意
请注意,分布的方法(即 `pdf`、`dpdf` 等)不需要向量化。它们应接受并返回浮点数。
注意
也可以将 SciPy 分布作为参数传递。但是,请注意,对象并不总是具有某些生成器所需的所有信息,例如 TDR 方法的 PDF 导数。依赖 SciPy 分布还可能由于 `pdf` 和 `cdf` 等方法的向量化而降低性能。在这两种情况下,都可以实现一个自定义分布对象,该对象包含所有必需的方法且未向量化,如上例所示。如果想将数值逆变换方法应用于 SciPy 中定义的分布,也请参阅 scipy.stats.sampling.FastGeneratorInversion。
在上面的示例中,我们设置了一个 TransformedDensityRejection 方法的对象,用于从标准正态分布中采样。现在,我们可以通过调用 `rvs` 方法开始从我们的分布中采样。
rng.rvs()
0.02993054902042954
rng.rvs((5, 3))
array([[ 0.53298415, 1.43877957, 3.59914818],
[-0.84078139, -0.69554656, -0.52440591],
[ 0.01225487, -0.00454614, -0.28462863],
[ 0.82790149, -0.72765527, 1.20739908],
[-1.56792816, -1.15971132, -0.56065036]])
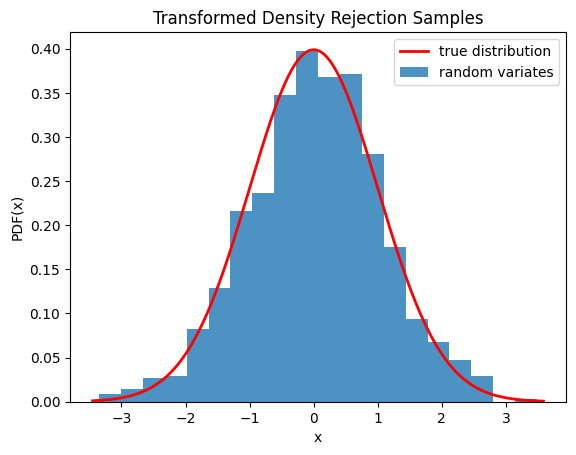
我们还可以通过可视化样本的直方图来检查样本是否从正确的分布中抽取。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
from scipy.stats.sampling import TransformedDensityRejection
from math import exp
class StandardNormal:
def pdf(self, x: float) -> float:
# note that the normalization constant isn't required
return exp(-0.5 * x*x)
def dpdf(self, x: float) -> float:
return -x * exp(-0.5 * x*x)
dist = StandardNormal()
urng = np.random.default_rng()
rng = TransformedDensityRejection(dist, random_state=urng)
rvs = rng.rvs(size=1000)
x = np.linspace(rvs.min()-0.1, rvs.max()+0.1, num=1000)
fx = norm.pdf(x)
plt.plot(x, fx, 'r-', lw=2, label='true distribution')
plt.hist(rvs, bins=20, density=True, alpha=0.8, label='random variates')
plt.xlabel('x')
plt.ylabel('PDF(x)')
plt.title('Transformed Density Rejection Samples')
plt.legend()
plt.show()
注意
请注意 scipy.stats 中存在的分布的 `rvs` 方法与这些生成器提供的方法之间的区别。UNU.RAN 生成器必须被认为是独立的,因为它们通常会产生与 scipy.stats 中等效分布产生的随机数流不同。在 scipy.stats.rv_continuous 中 `rvs` 的实现通常依赖 NumPy 模块 numpy.random 来处理已知分布(例如,正态分布、Beta 分布)以及其他分布的变换(例如,正态逆高斯 scipy.stats.norminvgauss 和对数正态 scipy.stats.lognorm 分布)。如果没有实现特定方法,scipy.stats.rv_continuous 默认为 CDF 的数值逆变换方法,该方法非常慢。由于 UNU.RAN 转换均匀随机数的方式与 SciPy 或 NumPy 不同,即使对于相同的均匀随机数流,生成的随机变量流也会不同。例如,SciPy 的 scipy.stats.norm 和 UNU.RAN 的 TransformedDensityRejection 的随机数流即使对于相同的 `random_state` 也不会相同。
from scipy.stats.sampling import norm, TransformedDensityRejection
from copy import copy
dist = StandardNormal()
urng1 = np.random.default_rng()
urng1_copy = copy(urng1)
rng = TransformedDensityRejection(dist, random_state=urng1)
rng.rvs()
# -1.526829048388144
norm.rvs(random_state=urng1_copy)
# 1.3194816698862635
我们可以传递一个 `domain` 参数来截断分布。
rng = TransformedDensityRejection(dist, domain=(-1, 1), random_state=urng)
rng.rvs((5, 3))
array([[-3.87146100e-01, -3.07151677e-01, 4.47624310e-01],
[ 4.48644826e-01, 3.20296629e-01, -2.60817423e-01],
[ 6.44967243e-01, 3.23975875e-01, 1.55647870e-01],
[-7.92407003e-04, -7.72789588e-01, -5.12837415e-01],
[-7.30184717e-01, 9.35027888e-01, 2.63935531e-01]])
无效和错误的参数由 SciPy 或 UNU.RAN 处理。后者抛出一个遵循通用格式的 UNURANError。
UNURANError: [objid: <object id>] <error code>: <reason> => <type of error>
其中
`
<object id>` 是 UNU.RAN 给出的对象 ID`
<error code>` 是代表错误类型的错误代码。`
<reason>` 是错误发生的原因。`
<type of error>` 是对错误类型的简短描述。
`<reason>` 显示了导致错误的原因。这本身应该包含足够的信息来帮助调试错误。此外,`<error id>` 和 `<type of error>` 可用于调查 UNU.RAN 中不同类别的错误。所有错误代码及其描述的完整列表可在 UNU.RAN 用户手册的第 8.4 节中找到。
UNU.RAN 生成的错误示例如下所示:
UNURANError: [objid: TDR.003] 50 : PDF(x) < 0.! => (generator) (possible) invalid data
这表明 UNU.RAN 未能初始化 ID 为 `TDR.003` 的对象,因为 PDF 小于 0,即为负值。这属于“生成器可能存在无效数据”类型,错误代码为 50。
UNU.RAN 抛出的警告也遵循相同的格式。