scipy.special.stdtrit#
- scipy.special.stdtrit(df, p, out=None) = <ufunc 'stdtrit'>#
学生 t 分布的第 p 个分位数。
此函数是学生 t 分布累积分布函数 (CDF) 的逆函数,返回满足 stdtr(df, t) = p 的 t 值。
返回参数 t,使得 stdtr(df, t) 等于 p。
- 参数:
- df类数组对象
自由度
- p类数组对象
概率
- outndarray, 可选的
用于存储函数结果的可选输出数组
- 返回:
- t标量或 ndarray
t 值,使得
stdtr(df, t) == p
另请参阅
stdtr学生 t 累积分布函数
stdtridfstdtr 关于 df 的逆函数
scipy.stats.t学生 t 分布
备注
学生 t 分布也可作为
scipy.stats.t使用。与scipy.stats.t的ppf方法相比,直接调用stdtrit可以提高性能(参见下面的最后一个示例)。stdtrit除了 NumPy 之外,还对与 Python 数组 API 标准兼容的后端提供实验性支持。请考虑通过设置环境变量SCIPY_ARRAY_API=1并提供 CuPy、PyTorch、JAX 或 Dask 数组作为数组参数来测试这些功能。支持以下后端和设备(或其他功能)组合。库
CPU
GPU
NumPy
✅
不适用
CuPy
不适用
✅
PyTorch
✅
⛔
JAX
⛔
⛔
Dask
✅
不适用
有关更多信息,请参阅对数组 API 标准的支持。
示例
stdtrit表示学生 t 分布 CDF 的逆函数,该 CDF 可作为stdtr使用。在这里,我们计算df在x=1处的 CDF。stdtrit随后在给定相同的 df 值和计算出的 CDF 值的情况下,返回1(在浮点误差范围内)。>>> import numpy as np >>> from scipy.special import stdtr, stdtrit >>> import matplotlib.pyplot as plt >>> df = 3 >>> x = 1 >>> cdf_value = stdtr(df, x) >>> stdtrit(df, cdf_value) 0.9999999994418539
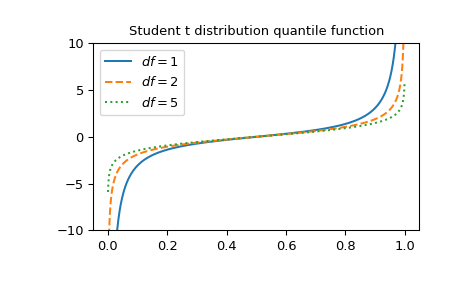
绘制函数在三种不同自由度下的曲线。
>>> x = np.linspace(0, 1, 1000) >>> parameters = [(1, "solid"), (2, "dashed"), (5, "dotted")] >>> fig, ax = plt.subplots() >>> for (df, linestyle) in parameters: ... ax.plot(x, stdtrit(df, x), ls=linestyle, label=f"$df={df}$") >>> ax.legend() >>> ax.set_ylim(-10, 10) >>> ax.set_title("Student t distribution quantile function") >>> plt.show()
通过为 df 提供 NumPy 数组或列表,可以同时计算该函数在多个自由度下的值。
>>> stdtrit([1, 2, 3], 0.7) array([0.72654253, 0.6172134 , 0.58438973])
通过为 df 和 p 提供形状兼容用于广播的数组,可以同时计算函数在多个点和多个不同自由度下的值。计算
stdtrit在 3 个自由度下的 4 个点,结果为一个 3x4 形状的数组。>>> dfs = np.array([[1], [2], [3]]) >>> p = np.array([0.2, 0.4, 0.7, 0.8]) >>> dfs.shape, p.shape ((3, 1), (4,))
>>> stdtrit(dfs, p) array([[-1.37638192, -0.3249197 , 0.72654253, 1.37638192], [-1.06066017, -0.28867513, 0.6172134 , 1.06066017], [-0.97847231, -0.27667066, 0.58438973, 0.97847231]])
t 分布也可作为
scipy.stats.t使用。直接调用stdtrit比调用scipy.stats.t的ppf方法快得多。为了获得相同的结果,必须使用以下参数化:scipy.stats.t(df).ppf(x) = stdtrit(df, x)。>>> from scipy.stats import t >>> df, x = 3, 0.5 >>> stdtrit_result = stdtrit(df, x) # this can be faster than below >>> stats_result = t(df).ppf(x) >>> stats_result == stdtrit_result # test that results are equal True