UnivariateSpline#
- 类 scipy.interpolate.UnivariateSpline(x, y, w=None, bbox=[None, None], k=3, s=None, ext=0, check_finite=False)[source]#
对给定数据集进行的一维平滑样条拟合。
旧版
此类别被视为旧版,将不再接收更新。虽然我们目前没有计划将其移除,但我们建议新代码使用更现代的替代方案。具体来说,我们建议改用
make_splrep。将 k 次样条 y = spl(x) 拟合到提供的 x, y 数据。s 通过指定平滑条件来确定结点的数量。
- 参数:
- x(N,) 数组形式
一维独立输入数据数组。必须是递增的;如果 s 为 0,则必须是严格递增的。
- y(N,) 数组形式
一维依赖输入数据数组,与 x 长度相同。
- w(N,) 数组形式,可选
样条拟合的权重。必须为正。如果 w 为 None,则所有权重均为 1。默认值为 None。
- bbox(2,) 数组形式,可选
指定近似区间边界的2元序列。如果 bbox 为 None,则
bbox=[x[0], x[-1]]。默认值为 None。- kint,可选
平滑样条的次数。必须介于 1 和 5 之间(含1和5)。
k = 3表示三次样条。默认值为 3。- sfloat 或 None,可选
用于选择结点数的正平滑因子。结点数将增加直到满足平滑条件
sum((w[i] * (y[i]-spl(x[i])))**2, axis=0) <= s
然而,由于数值问题,实际条件是
abs(sum((w[i] * (y[i]-spl(x[i])))**2, axis=0) - s) < 0.001 * s
如果 s 为 None,则对于使用所有数据点的平滑样条,s 将被设置为 len(w)。如果为 0,样条将通过所有数据点进行插值。这等同于
InterpolatedUnivariateSpline。默认值为 None。用户可以使用 s 来控制拟合的紧密性和平滑度之间的权衡。较大的 s 意味着更多的平滑,而较小的值则表示较少的平滑。推荐的 s 值取决于权重 w。如果权重代表 y 的标准差的倒数,那么一个好的 s 值应该在 (m-sqrt(2*m),m+sqrt(2*m)) 范围内找到,其中 m 是 x、y 和 w 中的数据点数量。这意味着如果1/w[i]是y[i]的标准差的估计值,则s = len(w)应该是一个好值。- extint 或 str,可选
控制结序列定义区间之外元素的外推模式。
如果 ext=0 或 ‘extrapolate’,返回外推值。
如果 ext=1 或 ‘zeros’,返回 0
如果 ext=2 或 ‘raise’,引发 ValueError
如果 ext=3 或 ‘const’,返回边界值。
默认值为 0。
- check_finitebool,可选
是否检查输入数组仅包含有限数。禁用此功能可能会提高性能,但如果输入包含无穷大或 NaN,则可能会导致问题(崩溃、无法终止或无意义的结果)。默认值为 False。
方法
__call__(x[, nu, ext])在位置 x 处评估样条(或其 nu 阶导数)。
antiderivative([n])构造一个新样条,表示此样条的原函数。
derivative([n])构造一个新样条,表示此样条的导数。
derivatives(x)返回样条在点 x 处的所有导数。
返回样条系数。
返回样条内部结点的位置。
返回样条近似的残差平方和(加权)。
integral(a, b)返回样条在给定两点之间的定积分。
roots()返回样条的零点。
使用给定的平滑因子 s 和上次调用时找到的结点继续样条计算。
validate_input
另请参阅
BivariateSpline双变量样条的基类。
SmoothBivariateSpline通过给定点的平滑双变量样条
LSQBivariateSpline使用加权最小二乘拟合的双变量样条
RectSphereBivariateSpline球面上矩形网格上的双变量样条
SmoothSphereBivariateSpline球坐标系中的平滑双变量样条
LSQSphereBivariateSpline球坐标系中使用加权最小二乘拟合的双变量样条
RectBivariateSpline矩形网格上的双变量样条
InterpolatedUnivariateSpline给定数据集的插值一维样条。
bisplrep查找曲面的双变量 B 样条表示的函数
bisplev评估双变量 B 样条及其导数的函数
splrep查找一维曲线的 B 样条表示的函数
splev评估 B 样条或其导数的函数
sproot查找三次 B 样条根的函数
splint评估 B 样条在给定两点之间的定积分的函数
spalde评估 B 样条所有导数的函数
说明
数据点的数量必须大于样条次数 k。
NaN 处理:如果输入数组包含
nan值,结果将不可用,因为底层的样条拟合例程无法处理nan。一个解决方法是对非数字数据点使用零权重>>> import numpy as np >>> from scipy.interpolate import UnivariateSpline >>> x, y = np.array([1, 2, 3, 4]), np.array([1, np.nan, 3, 4]) >>> w = np.isnan(y) >>> y[w] = 0. >>> spl = UnivariateSpline(x, y, w=~w)
请注意需要将
nan替换为数值(只要相应权重为零,精确值并不重要)。参考文献
[1]P. Dierckx, “An algorithm for smoothing, differentiation and integration of experimental data using spline functions”, J.Comp.Appl.Maths 1 (1975) 165-184.
[2]P. Dierckx, “A fast algorithm for smoothing data on a rectangular grid while using spline functions”, SIAM J.Numer.Anal. 19 (1982) 1286-1304.
[3]P. Dierckx, “An improved algorithm for curve fitting with spline functions”, report tw54, Dept. Computer Science,K.U. Leuven, 1981.
[4]P. Dierckx, “Curve and surface fitting with splines”, Monographs on Numerical Analysis, Oxford University Press, 1993.
示例
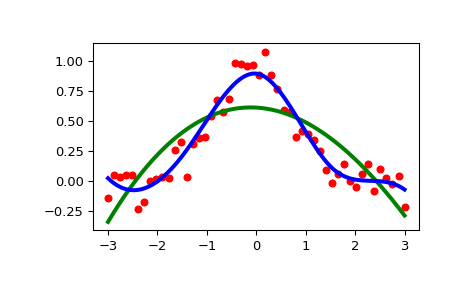
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from scipy.interpolate import UnivariateSpline >>> rng = np.random.default_rng() >>> x = np.linspace(-3, 3, 50) >>> y = np.exp(-x**2) + 0.1 * rng.standard_normal(50) >>> plt.plot(x, y, 'ro', ms=5)
使用平滑参数的默认值
>>> spl = UnivariateSpline(x, y) >>> xs = np.linspace(-3, 3, 1000) >>> plt.plot(xs, spl(xs), 'g', lw=3)
手动更改平滑量
>>> spl.set_smoothing_factor(0.5) >>> plt.plot(xs, spl(xs), 'b', lw=3) >>> plt.show()