RectSphereBivariateSpline#
- class scipy.interpolate.RectSphereBivariateSpline(u, v, r, s=0.0, pole_continuity=False, pole_values=None, pole_exact=False, pole_flat=False)[source]#
在球体上的矩形网格上进行二元样条逼近。
可用于数据平滑。
0.11.0 版本新增。
- 参数:
- uarray_like
1-D 数组,包含严格升序排列的余纬坐标。坐标必须以弧度为单位,并且位于开区间
(0, pi)内。- varray_like
1-D 数组,包含严格升序排列的经度坐标。坐标必须以弧度为单位。第一个元素 (
v[0]) 必须位于区间[-pi, pi)内。最后一个元素 (v[-1]) 必须满足v[-1] <= v[0] + 2*pi。- rarray_like
2-D 数据数组,形状为
(u.size, v.size)。- sfloat, optional
用于估计条件的正平滑因子(
s=0用于插值)。- pole_continuitybool or (bool, bool), optional
在极点
u=0(pole_continuity[0]) 和u=pi(pole_continuity[1]) 处的连续性阶数。当此参数为 True 或 False 时,极点处的连续性阶数分别为 1 或 0。默认为 False。- pole_valuesfloat or (float, float), optional
极点
u=0和u=pi处的数据值。整个参数或每个单独的元素都可以为 None。默认为 None。- pole_exactbool or (bool, bool), optional
极点
u=0和u=pi处数据值的精确性。如果为 True,则该值被视为正确的函数值,并将精确拟合。如果为 False,则该值将被视为与其他数据值一样的数据值。默认为 False。- pole_flatbool or (bool, bool), optional
对于极点
u=0和u=pi,指定近似值是否具有消失的导数。默认为 False。
方法
__call__(theta, phi[, dtheta, dphi, grid])在给定位置评估样条或其导数。
ev(theta, phi[, dtheta, dphi])在点处评估样条。
返回样条系数。
返回一个元组 (tx,ty),其中 tx,ty 分别包含样条相对于 x、y 变量的节点位置。
返回样条逼近的平方残差加权和:sum ((w[i]*(z[i]-s(x[i],y[i])))**2,axis=0)
partial_derivative(dx, dy)构造一个表示此样条的偏导数的新样条。
另请参阅
BivariateSpline二元样条的基类。
UnivariateSpline拟合给定数据点的平滑一元样条。
SmoothBivariateSpline通过给定点的平滑二元样条
LSQBivariateSpline使用加权最小二乘拟合的二元样条
SmoothSphereBivariateSpline球坐标系中的平滑二元样条
LSQSphereBivariateSpline球坐标系中使用加权最小二乘拟合的二元样条
RectBivariateSpline矩形网格上的二元样条。
bisplrep一个函数,用于查找曲面的二元 B 样条表示
bisplev一个函数,用于评估二元 B 样条及其导数
注释
目前,仅支持平滑样条逼近(FITPACK 例程中的
iopt[0] = 0和iopt[0] = 1)。精确的最小二乘样条逼近尚未实现。实际执行插值时,请求的 v 值必须位于与原始 v 值相同的 2pi 长度区间内。
更多信息,请参阅 FITPACK 网站上关于此函数的信息。
示例
假设我们有一个粗网格上的全局数据
>>> import numpy as np >>> lats = np.linspace(10, 170, 9) * np.pi / 180. >>> lons = np.linspace(0, 350, 18) * np.pi / 180. >>> data = np.dot(np.atleast_2d(90. - np.linspace(-80., 80., 18)).T, ... np.atleast_2d(180. - np.abs(np.linspace(0., 350., 9)))).T
我们想将其插值到全局一度网格
>>> new_lats = np.linspace(1, 180, 180) * np.pi / 180 >>> new_lons = np.linspace(1, 360, 360) * np.pi / 180 >>> new_lats, new_lons = np.meshgrid(new_lats, new_lons)
我们需要设置插值器对象
>>> from scipy.interpolate import RectSphereBivariateSpline >>> lut = RectSphereBivariateSpline(lats, lons, data)
最后,我们对数据进行插值。
RectSphereBivariateSpline对象只接受 1-D 数组作为输入,因此我们需要进行一些重塑。>>> data_interp = lut.ev(new_lats.ravel(), ... new_lons.ravel()).reshape((360, 180)).T
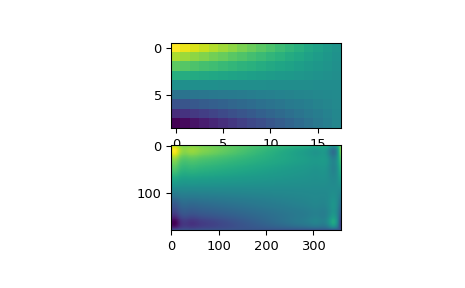
观察原始数据和插值数据,可以看出插值器很好地再现了原始数据
>>> import matplotlib.pyplot as plt >>> fig = plt.figure() >>> ax1 = fig.add_subplot(211) >>> ax1.imshow(data, interpolation='nearest') >>> ax2 = fig.add_subplot(212) >>> ax2.imshow(data_interp, interpolation='nearest') >>> plt.show()
选择
s的最佳值可能是一项微妙的任务。s的推荐值取决于数据值的准确性。如果用户对数据的统计误差有了解,她也可以找到s的适当估计。假设她指定了正确的s,插值器将使用一个样条f(u,v),它精确地再现了数据底层的函数,她可以评估sum((r(i,j)-s(u(i),v(j)))**2)来找到这个s的良好估计。例如,如果她知道她的r(i,j)值的统计误差不大于 0.1,她可能期望一个好的s值不应大于u.size * v.size * (0.1)**2。如果对
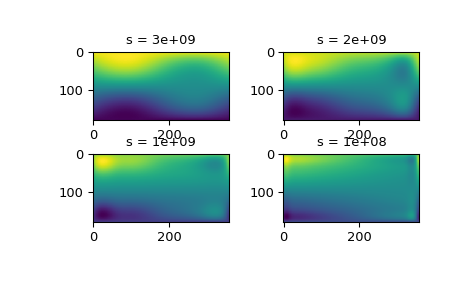
r(i,j)的统计误差一无所知,则必须通过试错法确定s。最好的方法是先从一个非常大的s值开始(以确定最小二乘多项式以及s对应的上限fp0),然后逐步减小s的值(例如,开始时按 10 的因子减小,即s = fp0 / 10, fp0 / 100, ...,当近似结果显示更多细节时更谨慎),以获得更紧密的拟合。不同
s值的插值结果为这个过程提供了一些见解>>> fig2 = plt.figure() >>> s = [3e9, 2e9, 1e9, 1e8] >>> for idx, sval in enumerate(s, 1): ... lut = RectSphereBivariateSpline(lats, lons, data, s=sval) ... data_interp = lut.ev(new_lats.ravel(), ... new_lons.ravel()).reshape((360, 180)).T ... ax = fig2.add_subplot(2, 2, idx) ... ax.imshow(data_interp, interpolation='nearest') ... ax.set_title(f"s = {sval:g}") >>> plt.show()