curve_fit#
- scipy.optimize.curve_fit(f, xdata, ydata, p0=None, sigma=None, absolute_sigma=False, check_finite=None, bounds=(-inf, inf), method=None, jac=None, *, full_output=False, nan_policy=None, **kwargs)[source]#
使用非线性最小二乘法将函数 f 拟合到数据。
假定
ydata = f(xdata, *params) + eps。- 参数:
- f可调用对象
模型函数,f(x, ...)。它必须将自变量作为第一个参数,并将要拟合的参数作为单独的剩余参数。
- xdataarray_like
测量数据时的自变量。对于具有 k 个预测变量的函数,通常应为 M 长度序列或 (k,M) 形状的数组,如果它是类数组对象,则每个元素都应可转换为浮点数。
- ydataarray_like
因变量数据,一个长度为 M 的数组 - 名义上为
f(xdata, ...)。- p0array_like, 可选
参数的初始猜测(长度 N)。如果为 None,则所有初始值都将是 1(如果可以使用内省确定函数的参数数量,否则会引发 ValueError)。
- sigmaNone 或标量或 M 长度序列或 MxM 数组, 可选
确定 ydata 中的不确定性。如果我们将残差定义为
r = ydata - f(xdata, *popt),则 sigma 的解释取决于其维度数量标量或 1-D sigma 应包含 ydata 中误差的标准差值。在这种情况下,优化的函数是
chisq = sum((r / sigma) ** 2)。2-D sigma 应包含 ydata 中误差的协方差矩阵。在这种情况下,优化的函数是
chisq = r.T @ inv(sigma) @ r。0.19 版本新增。
None (默认) 等效于填充了 1 的 1-D sigma。
- absolute_sigmabool, 可选
如果为 True,sigma 以绝对意义使用,估计的参数协方差 pcov 反映这些绝对值。
如果为 False(默认),则仅 sigma 值的相对大小重要。返回的参数协方差矩阵 pcov 基于按常数因子缩放 sigma。这个常数通过要求在使用缩放的 sigma 时,最优参数 popt 的约化 chisq 等于 1 来设置。换句话说,sigma 被缩放以匹配拟合后残差的样本方差。默认值为 False。数学上,
pcov(absolute_sigma=False) = pcov(absolute_sigma=True) * chisq(popt)/(M-N)- check_finitebool, 可选
如果为 True,检查输入数组是否包含 NaN 或无穷大,如果包含则引发 ValueError。将此参数设置为 False 如果输入数组包含 NaN,可能会默默地产生无意义的结果。如果未显式指定 nan_policy,则默认值为 True,否则为 False。
- boundsarray_like 或
Bounds的 2 元组, 可选 参数的下限和上限。默认为无界。有两种指定边界的方法
Bounds类的实例。array_like 的 2 元组:元组的每个元素必须是长度等于参数数量的数组,或者是标量(在这种情况下,边界对所有参数都相同)。使用
np.inf和适当的符号来禁用所有或部分参数的边界。
- method{'lm', 'trf', 'dogbox'}, 可选
用于优化的方法。有关更多详细信息,请参见
least_squares。对于无约束问题,默认值为 'lm';如果提供了 bounds,则为 'trf'。当观测数量少于变量数量时,'lm' 方法不起作用,在这种情况下请使用 'trf' 或 'dogbox'。0.17 版本新增。
- jac可调用对象, 字符串或 None, 可选
具有签名
jac(x, ...)的函数,用于计算模型函数相对于参数的雅可比矩阵,作为一个密集的类数组结构。它将根据提供的 sigma 进行缩放。如果为 None(默认),雅可比矩阵将通过数值方法估计。'trf' 和 'dogbox' 方法的字符串关键字可用于选择有限差分方案,请参见least_squares。0.18 版本新增。
- full_output布尔值, 可选
如果为 True,此函数将返回额外信息:infodict、mesg 和 ier。
1.9 版本新增。
- nan_policy{'raise', 'omit', None}, 可选
定义输入包含 NaN 时如何处理。以下选项可用(默认为 None)
'raise': 抛出错误
'omit': 忽略 NaN 值执行计算
None: 不对 NaN 执行特殊处理(除了 check_finite 所做的);存在 NaN 时的行为取决于实现,并且可能改变。
请注意,如果明确指定此值(不是 None),check_finite 将被设置为 False。
1.11 版本新增。
- **kwargs
传递给
leastsq(当method='lm'时) 或least_squares(否则) 的关键字参数。
- 返回:
- popt数组
参数的最优值,使得
f(xdata, *popt) - ydata的残差平方和最小化。- pcov2-D 数组
popt 的估计近似协方差。对角线提供了参数估计的方差。要计算参数的一个标准差误差,请使用
perr = np.sqrt(np.diag(pcov))。请注意,cov 和参数误差估计之间的关系是基于模型函数在最优值附近进行线性近似推导的 [1]。当此近似变得不准确时,cov 可能无法提供准确的不确定性度量。如上所述,sigma 参数如何影响估计的协方差取决于 absolute_sigma 参数。
如果解处的雅可比矩阵不是满秩,则 'lm' 方法返回一个填充了
np.inf的矩阵,而 'trf' 和 'dogbox' 方法使用 Moore-Penrose 伪逆来计算协方差矩阵。具有大条件数(例如使用numpy.linalg.cond计算)的协方差矩阵可能表明结果不可靠。- infodictdict (仅当 full_output 为 True 时返回)
包含以下键的可选输出字典
nfev函数调用的次数。与 'lm' 方法不同,'trf' 和 'dogbox' 方法不计算数值雅可比近似的函数调用。
fvec在解处评估的残差值,对于 1-D sigma,这是
(f(x, *popt) - ydata)/sigma。fjac最终近似雅可比矩阵的 QR 分解中 R 矩阵的置换,按列存储。与 ipvt 一起,可以近似估计的协方差。只有 'lm' 方法提供此信息。
ipvt一个长度为 N 的整数数组,定义一个置换矩阵 p,使得 fjac*p = q*r,其中 r 是上三角矩阵,对角线元素的幅度非增。p 的第 j 列是单位矩阵的第 ipvt(j) 列。只有 'lm' 方法提供此信息。
qtf向量 (transpose(q) * fvec)。只有 'lm' 方法提供此信息。
1.9 版本新增。
- mesgstr (仅当 full_output 为 True 时返回)
提供有关解决方案信息的字符串消息。
1.9 版本新增。
- ierint (仅当 full_output 为 True 时返回)
一个整数标志。如果它等于 1、2、3 或 4,则找到解决方案。否则,未找到解决方案。在这两种情况下,可选输出变量 mesg 提供更多信息。
1.9 版本新增。
- 引发:
- ValueError
如果 ydata 或 xdata 包含 NaN,或者使用了不兼容的选项。
- RuntimeError
如果最小二乘法最小化失败。
- OptimizeWarning
如果无法估计参数的协方差。
另请参见
least_squares最小化非线性函数平方和。
scipy.stats.linregress计算两组测量的线性最小二乘回归。
注意
用户应确保输入 xdata、ydata 以及 f 的输出为
float64,否则优化可能会返回不正确的结果。使用
method='lm'时,算法通过leastsq使用 Levenberg-Marquardt 算法。请注意,此算法只能处理无约束问题。箱式约束可以通过 'trf' 和 'dogbox' 方法处理。有关更多信息,请参阅
least_squares的文档字符串。要拟合的参数必须具有相似的尺度。多个数量级的差异可能导致不正确的结果。对于 'trf' 和 'dogbox' 方法,可以使用 x_scale 关键字参数来缩放参数。
curve_fit用于参数的局部优化,以最小化残差的平方和。对于全局优化、其他目标函数选择以及其他高级功能,请考虑使用 SciPy 的全局优化工具或 LMFIT 包。参考文献
[1]K. Vugrin et al. 地下水流中非线性回归的置信区域估计技术:三个案例研究。Water Resources Research, Vol. 43, W03423, DOI:10.1029/2005WR004804
示例
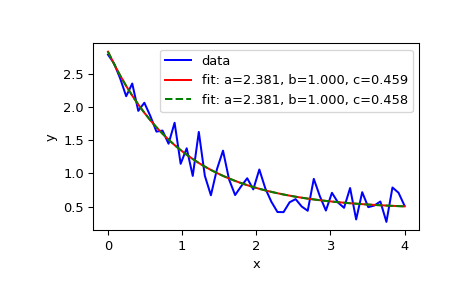
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from scipy.optimize import curve_fit
>>> def func(x, a, b, c): ... return a * np.exp(-b * x) + c
定义带有噪声的拟合数据
>>> xdata = np.linspace(0, 4, 50) >>> y = func(xdata, 2.5, 1.3, 0.5) >>> rng = np.random.default_rng() >>> y_noise = 0.2 * rng.normal(size=xdata.size) >>> ydata = y + y_noise >>> plt.plot(xdata, ydata, 'b-', label='data')
拟合函数 func 的参数 a, b, c
>>> popt, pcov = curve_fit(func, xdata, ydata) >>> popt array([2.56274217, 1.37268521, 0.47427475]) >>> plt.plot(xdata, func(xdata, *popt), 'r-', ... label='fit: a=%5.3f, b=%5.3f, c=%5.3f' % tuple(popt))
将优化约束在区域
0 <= a <= 3,0 <= b <= 1和0 <= c <= 0.5>>> popt, pcov = curve_fit(func, xdata, ydata, bounds=(0, [3., 1., 0.5])) >>> popt array([2.43736712, 1. , 0.34463856]) >>> plt.plot(xdata, func(xdata, *popt), 'g--', ... label='fit: a=%5.3f, b=%5.3f, c=%5.3f' % tuple(popt))
>>> plt.xlabel('x') >>> plt.ylabel('y') >>> plt.legend() >>> plt.show()
为获得可靠结果,模型 func 不应过度参数化;冗余参数可能导致协方差矩阵不可靠,在某些情况下还会导致拟合质量较差。作为快速检查模型是否可能过度参数化的方法,计算协方差矩阵的条件数
>>> np.linalg.cond(pcov) 34.571092161547405 # may vary
这个值很小,所以不必过于担心。但是,如果我们在 func 中添加第四个参数
d,其效果与a相同>>> def func2(x, a, b, c, d): ... return a * d * np.exp(-b * x) + c # a and d are redundant >>> popt, pcov = curve_fit(func2, xdata, ydata) >>> np.linalg.cond(pcov) 1.13250718925596e+32 # may vary
如此大的值令人担忧。协方差矩阵的对角线元素与拟合的不确定性相关,提供了更多信息
>>> np.diag(pcov) array([1.48814742e+29, 3.78596560e-02, 5.39253738e-03, 2.76417220e+28]) # may vary
请注意,第一项和最后一项远大于其他元素,这表明这些参数的最优值是模糊的,并且模型中只需要其中一个参数。
如果 f 的最优参数相差多个数量级,则得到的拟合可能不准确。有时,
curve_fit可能无法找到任何结果>>> ydata = func(xdata, 500000, 0.01, 15) >>> try: ... popt, pcov = curve_fit(func, xdata, ydata, method = 'trf') ... except RuntimeError as e: ... print(e) Optimal parameters not found: The maximum number of function evaluations is exceeded.
如果参数尺度事先大致已知,可以在 x_scale 参数中定义
>>> popt, pcov = curve_fit(func, xdata, ydata, method = 'trf', ... x_scale = [1000, 1, 1]) >>> popt array([5.00000000e+05, 1.00000000e-02, 1.49999999e+01])