least_squares#
- scipy.optimize.least_squares(fun, x0, jac='2-point', bounds=(-inf, inf), method='trf', ftol=1e-08, xtol=1e-08, gtol=1e-08, x_scale=None, loss='linear', f_scale=1.0, diff_step=None, tr_solver=None, tr_options=None, jac_sparsity=None, max_nfev=None, verbose=0, args=(), kwargs=None, callback=None, workers=None)[source]#
解决带有变量边界的非线性最小二乘问题。
给定残差 f(x)(一个 m 维实数函数,具有 n 个实数变量)和损失函数 rho(s)(一个标量函数),
least_squares会找到成本函数 F(x) 的局部最小值minimize F(x) = 0.5 * sum(rho(f_i(x)**2), i = 0, ..., m - 1) subject to lb <= x <= ub
损失函数 rho(s) 的目的是减少异常值对解的影响。
- 参数:
- funcallable
计算残差向量的函数,其签名是
fun(x, *args, **kwargs),即最小化是根据其第一个参数进行的。传递给此函数的参数x是形状为 (n,) 的 ndarray(即使 n=1 也绝不是标量)。它必须分配并返回形状为 (m,) 的一维 array_like 或标量。如果参数x是复数或函数fun返回复数残差,则必须将其包装在一个接受实数参数的实数函数中,如示例部分末尾所示。- x0形状为 (n,) 的 array_like 或 float
自变量的初始猜测。如果为 float,则将被视为只有一个元素的一维数组。当 method 为 'trf' 时,初始猜测可能会略微调整以使其充分位于给定 bounds 内。
- jac{'2-point', '3-point', 'cs', callable},可选
计算雅可比矩阵的方法(m 行 n 列矩阵,其中元素 (i, j) 是 f[i] 对 x[j] 的偏导数)。关键字选择用于数值估计的有限差分方案。'3-point' 方案更准确,但需要的操作是 '2-point'(默认)的两倍。'cs' 方案使用复数步长,虽然可能是最准确的,但仅适用于 fun 正确处理复数输入并可以解析地扩展到复平面时。如果为可调用对象,则用作
jac(x, *args, **kwargs)并应返回雅可比的良好近似值(或精确值)作为 array_like(应用 np.atleast_2d)、稀疏数组(为性能优选 csr_array)或scipy.sparse.linalg.LinearOperator。1.16.0 版中更改: 支持 'lm' 方法使用 '3-point'、'cs' 关键字。此前 'lm' 仅限于 '2-point' 和可调用对象。
- bounds2-tuple of array_like 或
Bounds,可选 有两种指定边界的方式
Bounds类的实例自变量的下限和上限。默认为无边界。每个数组必须与 x0 的大小匹配或为标量,在后一种情况下,所有变量的边界将相同。使用具有适当符号的
np.inf可以禁用所有或某些变量的边界。
- method{'trf', 'dogbox', 'lm'},可选
执行最小化的算法。
'trf' : 信赖域反射算法,特别适用于带有边界的大型稀疏问题。通常是稳健的方法。
'dogbox' : 带有矩形信赖域的 dogleg 算法,典型用例是带有边界的小问题。不推荐用于雅可比秩亏损的问题。
'lm' : MINPACK 中实现的 Levenberg-Marquardt 算法。不处理边界和稀疏雅可比。通常是小型无约束问题最有效的方法。
默认是 'trf'。有关更多信息,请参阅注释。
- ftolfloat 或 None,可选
由成本函数变化引起的终止容差。默认值为 1e-8。当
dF < ftol * F并且在最后一步中局部二次模型与真实模型之间有足够的一致性时,优化过程停止。如果为 None 且 'method' 不是 'lm',则此条件下的终止将被禁用。如果 'method' 是 'lm',则此容差必须高于机器 epsilon。
- xtolfloat 或 None,可选
由自变量变化引起的终止容差。默认值为 1e-8。确切的条件取决于所使用的 method
对于 'trf' 和 'dogbox' :
norm(dx) < xtol * (xtol + norm(x))。对于 'lm' :
Delta < xtol * norm(xs),其中Delta是信赖域半径,xs是根据 x_scale 参数(参见下文)缩放的x值。
如果为 None 且 'method' 不是 'lm',则此条件下的终止将被禁用。如果 'method' 是 'lm',则此容差必须高于机器 epsilon。
- gtolfloat 或 None,可选
由梯度范数引起的终止容差。默认值为 1e-8。确切的条件取决于所使用的 method
对于 'trf' :
norm(g_scaled, ord=np.inf) < gtol,其中g_scaled是为考虑边界存在而缩放的梯度值 [STIR]。对于 'dogbox' :
norm(g_free, ord=np.inf) < gtol,其中g_free是相对于不在边界上的最优状态变量的梯度。对于 'lm' : 雅可比列与残差向量之间夹角的余弦最大绝对值小于 gtol,或者残差向量为零。
如果为 None 且 'method' 不是 'lm',则此条件下的终止将被禁用。如果 'method' 是 'lm',则此容差必须高于机器 epsilon。
- x_scale{None, array_like, 'jac'},可选
每个变量的特征尺度。设置 x_scale 等效于用缩放变量
xs = x / x_scale重构问题。另一种观点是,沿第 j 维的信赖域大小与x_scale[j]成比例。通过设置 x_scale 使沿任何缩放变量给定大小的步长对成本函数产生类似影响,可以实现更好的收敛。如果设置为 'jac',则使用雅可比矩阵列的逆范数迭代更新尺度(如 [JJMore] 中所述)。每种方法的默认尺度(即如果x_scale is None)如下对于 'trf' :
x_scale == 1对于 'dogbox' :
x_scale == 1对于 'jac' :
x_scale == 'jac'
1.16.0 版中更改: 默认关键字值从 1 更改为 None,以表示使用默认的缩放方法。对于 'lm' 方法,默认缩放从 1 更改为 'jac'。这被发现能提供更好的性能,并且与
leastsq执行的缩放相同。- lossstr 或 callable,可选
确定损失函数。允许以下关键字值
'linear'(默认) :
rho(z) = z。给出标准的最小二乘问题。'soft_l1' :
rho(z) = 2 * ((1 + z)**0.5 - 1)。l1(绝对值)损失的平滑近似。通常是鲁棒最小二乘的良好选择。'huber' :
rho(z) = z if z <= 1 else 2*z**0.5 - 1。与 'soft_l1' 类似。'cauchy' :
rho(z) = ln(1 + z)。严重削弱异常值的影响,但可能导致优化过程中的困难。'arctan' :
rho(z) = arctan(z)。限制单个残差的最大损失,具有与 'cauchy' 相似的特性。
如果为可调用对象,它必须接受一维 ndarray
z=f**2并返回形状为 (3, m) 的 array_like,其中第 0 行包含函数值,第 1 行包含一阶导数,第 2 行包含二阶导数。'lm' 方法仅支持 'linear' 损失。- f_scalefloat,可选
内点和异常值残差之间软边距的值,默认为 1.0。损失函数计算如下
rho_(f**2) = C**2 * rho(f**2 / C**2),其中C是 f_scale,rho由 loss 参数确定。此参数对loss='linear'没有影响,但对于其他 loss 值则至关重要。- max_nfevNone 或 int,可选
对于所有方法,此参数控制每种方法使用的最大函数评估次数,不包括用于雅可比数值近似的评估。如果为 None(默认),则该值自动选择为 100 * n。
1.16.0 版中更改: 'lm' 方法的默认值更改为 100 * n,无论雅可比是可调用还是数值估计。此前,当使用估计雅可比时,默认值为 100 * n * (n + 1),因为该方法包含了估计中使用的评估。
- diff_stepNone 或 array_like,可选
确定雅可比有限差分近似的相对步长。实际步长计算为
x * diff_step。如果为 None(默认),则 diff_step 被视为所用有限差分方案的机器 epsilon 的常规“最优”幂 [NR]。- tr_solver{None, 'exact', 'lsmr'},可选
用于解决信赖域子问题的方法,仅与 'trf' 和 'dogbox' 方法相关。
'exact' 适用于雅可比矩阵稠密且问题规模不大的情况。每次迭代的计算复杂度与雅可比矩阵的奇异值分解相当。
'lsmr' 适用于雅可比矩阵稀疏且规模大的问题。它使用迭代过程
scipy.sparse.linalg.lsmr来寻找线性最小二乘问题的解,并且只需要矩阵-向量乘积评估。
如果为 None(默认),则根据第一次迭代返回的雅可比类型选择求解器。
- tr_optionsdict,可选
传递给信赖域求解器的关键字选项。
tr_solver='exact': tr_options 被忽略。tr_solver='lsmr':scipy.sparse.linalg.lsmr的选项。此外,method='trf'支持 'regularize' 选项(布尔值,默认为 True),它向正规方程添加正则化项,如果雅可比秩亏损,则可改善收敛性 [Byrd](式 3.4)。
- jac_sparsity{None, array_like, sparse array},可选
定义用于有限差分估计的雅可比矩阵的稀疏结构,其形状必须是 (m, n)。如果雅可比的每行中只有少数非零元素,提供稀疏结构将大大加快计算速度 [Curtis]。零条目表示雅可比中的相应元素恒为零。如果提供,则强制使用 'lsmr' 信赖域求解器。如果为 None(默认),则将使用稠密差分。对 'lm' 方法无效。
- verbose{0, 1, 2},可选
算法的详细程度
0(默认): 静默工作。
1 : 显示终止报告。
2 : 迭代过程中显示进度('lm' 方法不支持)。
- args, kwargstuple 和 dict,可选
传递给 fun 和 jac 的附加参数。两者默认均为空。调用签名是
fun(x, *args, **kwargs),jac 也是如此。- callbackNone 或 callable,可选
算法在每次迭代时调用的回调函数。这可用于在每个步骤打印或绘制优化结果,并根据用户定义的条件停止优化算法。仅为 trf 和 dogbox 方法实现。
签名是
callback(intermediate_result: OptimizeResult)intermediate_result 是一个 `scipy.optimize.OptimizeResult 对象,其中包含当前迭代的优化中间结果。
回调也支持类似
callback(x)的签名使用自省来确定调用哪个签名。
如果 callback 函数引发 StopIteration,优化算法将停止并返回状态码 -2。
在 1.16.0 版本中新增。
- workersmap-like callable,可选
一个 map-like 可调用对象,例如 multiprocessing.Pool.map,用于并行评估任何数值微分。此评估以
workers(fun, iterable)的形式执行。在 1.16.0 版本中新增。
- 返回:
- resultOptimizeResult
OptimizeResult,包含以下字段- xndarray,形状 (n,)
找到的解。
- costfloat
解处的成本函数值。
- funndarray,形状 (m,)
解处的残差向量。
- jacndarray, sparse array 或 LinearOperator, 形状 (m, n)
解处的修改雅可比矩阵,J^T J 是成本函数 Hessian 的 Gauss-Newton 近似。类型与算法使用的类型相同。
- gradndarray,形状 (m,)
解处的成本函数梯度。
- optimalityfloat
一阶最优性度量。在无约束问题中,它始终是梯度的均匀范数。在受约束问题中,它是迭代过程中与 gtol 进行比较的量。
- active_maskint 类型的 ndarray,形状 (n,)
每个分量显示相应的约束是否处于活跃状态(即变量是否处于边界上)
0 : 约束不活跃。
-1 : 下限活跃。
1 : 上限活跃。
对于 'trf' 方法可能有些随意,因为它生成一系列严格可行的迭代,并且 active_mask 是在容差阈值内确定的。
- nfevint
已执行的函数评估次数。此数字不包括用于数值雅可比近似的函数调用。
1.16.0 版中更改: 对于 'lm' 方法,不再包含用于数值雅可比近似的函数调用次数。这样做是为了使所有方法保持一致。
- njevint 或 None
已执行的雅可比评估次数。如果在 'lm' 方法中使用了数值雅可比近似,则将其设置为 None。
- statusint
算法终止的原因
-2 : 因回调函数引发 StopIteration 而终止。
-1 : 从 MINPACK 返回的输入参数状态不正确。
0 : 超出最大函数评估次数。
1 : gtol 终止条件满足。
2 : ftol 终止条件满足。
3 : xtol 终止条件满足。
4 : ftol 和 xtol 终止条件均满足。
- messagestr
终止原因的文字描述。
- successbool
如果满足其中一个收敛准则(status > 0),则为 True。
注释
'lm'(Levenberg-Marquardt)方法调用 MINPACK(lmder)中实现的最小二乘算法的包装器。它运行形如信赖域算法的 Levenberg-Marquardt 算法。该实现基于论文 [JJMore],它非常稳健高效,并包含许多巧妙的技巧。它应该是无约束问题的首选。请注意,它不支持边界。此外,当 m < n 时它不起作用。
'trf'(信赖域反射)方法的灵感来源于求解方程组的过程,这些方程组构成了 [STIR] 中提出的有界约束最小化问题的一阶最优性条件。该算法迭代地求解信赖域子问题,子问题由一个特殊的对角二次项增强,并且信赖域的形状由距边界的距离和梯度的方向决定。这些增强有助于避免直接进入边界并有效地探索变量的整个空间。为了进一步改善收敛性,算法考虑了从边界反射的搜索方向。为了遵守理论要求,算法保持迭代严格可行。对于稠密雅可比,信赖域子问题通过一种非常类似于 [JJMore] 中描述的方法(并在 MINPACK 中实现)的精确方法求解。与 MINPACK 实现的区别在于,雅可比矩阵的奇异值分解在每次迭代中只进行一次,而不是 QR 分解和一系列 Givens 旋转消除。对于大型稀疏雅可比,采用二维子空间方法解决信赖域子问题 [STIR]、[Byrd]。该子空间由缩放梯度和
scipy.sparse.linalg.lsmr提供的近似高斯-牛顿解张成。当没有施加约束时,该算法与 MINPACK 非常相似,并且通常具有可比的性能。该算法在无界和有界问题中都能稳健工作,因此被选为默认算法。'dogbox' 方法在信赖域框架中运行,但考虑矩形信赖域而非传统的椭球体 [Voglis]。当前信赖域与初始边界的交集仍然是矩形,因此在每次迭代中,受边界约束的二次最小化问题通过 Powell 的 dogleg 方法近似求解 [NumOpt]。所需的 Gauss-Newton 步长可以为稠密雅可比精确计算,或者通过
scipy.sparse.linalg.lsmr为大型稀疏雅可比近似计算。当雅可比的秩小于变量数量时,该算法可能表现出缓慢收敛。该算法通常在具有少量变量的有界问题中优于 'trf'。鲁棒损失函数按照 [BA] 中的描述实现。其思想是在每次迭代中修改残差向量和雅可比矩阵,使得计算出的梯度和 Gauss-Newton Hessian 近似与成本函数的真实梯度和 Hessian 近似相匹配。然后算法以正常方式进行,即,鲁棒损失函数作为标准最小二乘算法的简单包装器实现。
在 0.17.0 版本中新增。
参考文献
[STIR] (1,2,3)M. A. Branch, T. F. Coleman, and Y. Li, “A Subspace, Interior, and Conjugate Gradient Method for Large-Scale Bound-Constrained Minimization Problems,” SIAM Journal on Scientific Computing, Vol. 21, Number 1, pp 1-23, 1999。
[NR]William H. Press et. al., “Numerical Recipes. The Art of Scientific Computing. 3rd edition”, Sec. 5.7。
[Byrd] (1,2)R. H. Byrd, R. B. Schnabel and G. A. Shultz, “Approximate solution of the trust region problem by minimization over two-dimensional subspaces”, Math. Programming, 40, pp. 247-263, 1988。
[Curtis]A. Curtis, M. J. D. Powell, and J. Reid, “On the estimation of sparse Jacobian matrices”, Journal of the Institute of Mathematics and its Applications, 13, pp. 117-120, 1974。
[JJMore] (1,2,3)J. J. More, “The Levenberg-Marquardt Algorithm: Implementation and Theory,” Numerical Analysis, ed. G. A. Watson, Lecture Notes in Mathematics 630, Springer Verlag, pp. 105-116, 1977。
[Voglis]C. Voglis and I. E. Lagaris, “A Rectangular Trust Region Dogleg Approach for Unconstrained and Bound Constrained Nonlinear Optimization”, WSEAS International Conference on Applied Mathematics, Corfu, Greece, 2004。
[NumOpt]J. Nocedal and S. J. Wright, “Numerical optimization, 2nd edition”, Chapter 4。
[BA]B. Triggs et. al., “Bundle Adjustment - A Modern Synthesis”, Proceedings of the International Workshop on Vision Algorithms: Theory and Practice, pp. 298-372, 1999。
示例
在此示例中,我们寻找 Rosenbrock 函数的最小值,且独立变量无边界。
>>> import numpy as np >>> def fun_rosenbrock(x): ... return np.array([10 * (x[1] - x[0]**2), (1 - x[0])])
请注意,我们只提供了残差向量。算法将成本函数构建为残差平方和,这正是 Rosenbrock 函数。精确最小值在
x = [1.0, 1.0]。>>> from scipy.optimize import least_squares >>> x0_rosenbrock = np.array([2, 2]) >>> res_1 = least_squares(fun_rosenbrock, x0_rosenbrock) >>> res_1.x array([ 1., 1.]) >>> res_1.cost 9.8669242910846867e-30 >>> res_1.optimality 8.8928864934219529e-14
现在我们约束变量,使得先前的解变得不可行。具体来说,我们要求
x[1] >= 1.5,而x[0]不受约束。为此,我们以bounds=([-np.inf, 1.5], np.inf)的形式为least_squares指定 bounds 参数。我们还提供了解析雅可比。
>>> def jac_rosenbrock(x): ... return np.array([ ... [-20 * x[0], 10], ... [-1, 0]])
综合来看,我们看到新解位于边界上。
>>> res_2 = least_squares(fun_rosenbrock, x0_rosenbrock, jac_rosenbrock, ... bounds=([-np.inf, 1.5], np.inf)) >>> res_2.x array([ 1.22437075, 1.5 ]) >>> res_2.cost 0.025213093946805685 >>> res_2.optimality 1.5885401433157753e-07
现在我们为 100000 个变量的 Broyden 三对角向量值函数求解一个方程组(即,在最小值处成本函数应为零)
>>> def fun_broyden(x): ... f = (3 - x) * x + 1 ... f[1:] -= x[:-1] ... f[:-1] -= 2 * x[1:] ... return f
相应的雅可比矩阵是稀疏的。我们让算法通过有限差分来估计它,并提供雅可比的稀疏结构以显著加快此过程。
>>> from scipy.sparse import lil_array >>> def sparsity_broyden(n): ... sparsity = lil_array((n, n), dtype=int) ... i = np.arange(n) ... sparsity[i, i] = 1 ... i = np.arange(1, n) ... sparsity[i, i - 1] = 1 ... i = np.arange(n - 1) ... sparsity[i, i + 1] = 1 ... return sparsity ... >>> n = 100000 >>> x0_broyden = -np.ones(n) ... >>> res_3 = least_squares(fun_broyden, x0_broyden, ... jac_sparsity=sparsity_broyden(n)) >>> res_3.cost 4.5687069299604613e-23 >>> res_3.optimality 1.1650454296851518e-11
我们还将使用鲁棒损失函数来解决曲线拟合问题,以处理数据中的异常值。将模型函数定义为
y = a + b * exp(c * t),其中 t 是预测变量,y 是观测值,a、b、c 是要估计的参数。首先,定义生成带有噪声和异常值的数据的函数,定义模型参数,并生成数据。
>>> from numpy.random import default_rng >>> rng = default_rng() >>> def gen_data(t, a, b, c, noise=0., n_outliers=0, seed=None): ... rng = default_rng(seed) ... ... y = a + b * np.exp(t * c) ... ... error = noise * rng.standard_normal(t.size) ... outliers = rng.integers(0, t.size, n_outliers) ... error[outliers] *= 10 ... ... return y + error ... >>> a = 0.5 >>> b = 2.0 >>> c = -1 >>> t_min = 0 >>> t_max = 10 >>> n_points = 15 ... >>> t_train = np.linspace(t_min, t_max, n_points) >>> y_train = gen_data(t_train, a, b, c, noise=0.1, n_outliers=3)
定义用于计算残差和参数初始估计的函数。
>>> def fun(x, t, y): ... return x[0] + x[1] * np.exp(x[2] * t) - y ... >>> x0 = np.array([1.0, 1.0, 0.0])
计算标准最小二乘解
>>> res_lsq = least_squares(fun, x0, args=(t_train, y_train))
现在用两种不同的鲁棒损失函数计算两个解。f_scale 参数设置为 0.1,这意味着内点残差不应显著超过 0.1(使用的噪声水平)。
>>> res_soft_l1 = least_squares(fun, x0, loss='soft_l1', f_scale=0.1, ... args=(t_train, y_train)) >>> res_log = least_squares(fun, x0, loss='cauchy', f_scale=0.1, ... args=(t_train, y_train))
最后,绘制所有曲线。我们看到,通过选择适当的 loss,即使在存在强异常值的情况下,我们也可以获得接近最优的估计。但请记住,通常建议首先尝试 'soft_l1' 或 'huber' 损失(如果确实有必要),因为其他两个选项可能会在优化过程中造成困难。
>>> t_test = np.linspace(t_min, t_max, n_points * 10) >>> y_true = gen_data(t_test, a, b, c) >>> y_lsq = gen_data(t_test, *res_lsq.x) >>> y_soft_l1 = gen_data(t_test, *res_soft_l1.x) >>> y_log = gen_data(t_test, *res_log.x) ... >>> import matplotlib.pyplot as plt >>> plt.plot(t_train, y_train, 'o') >>> plt.plot(t_test, y_true, 'k', linewidth=2, label='true') >>> plt.plot(t_test, y_lsq, label='linear loss') >>> plt.plot(t_test, y_soft_l1, label='soft_l1 loss') >>> plt.plot(t_test, y_log, label='cauchy loss') >>> plt.xlabel("t") >>> plt.ylabel("y") >>> plt.legend() >>> plt.show()
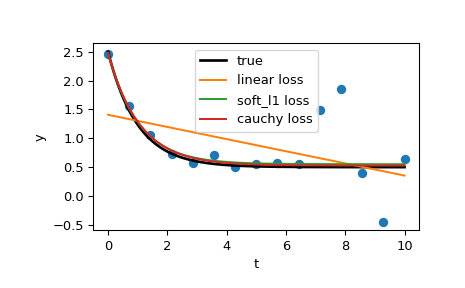
在下一个示例中,我们展示如何使用
least_squares()优化复数变量的复数值残差函数。考虑以下函数>>> def f(z): ... return z - (0.5 + 0.5j)
我们将其包装成一个实数变量的函数,通过简单地将实部和虚部作为独立变量来返回实数残差。
>>> def f_wrap(x): ... fx = f(x[0] + 1j*x[1]) ... return np.array([fx.real, fx.imag])
因此,我们不再优化一个 n 个复数变量的 m 维复数函数,而是优化一个 2n 个实数变量的 2m 维实数函数。
>>> from scipy.optimize import least_squares >>> res_wrapped = least_squares(f_wrap, (0.1, 0.1), bounds=([0, 0], [1, 1])) >>> z = res_wrapped.x[0] + res_wrapped.x[1]*1j >>> z (0.49999999999925893+0.49999999999925893j)