scipy.special.nbdtr#
- scipy.special.nbdtr(k, n, p, out=None) = <ufunc 'nbdtr'>#
负二项式累积分布函数。
返回负二项式分布概率质量函数中从 0 到 k 的项之和,
\[F = \sum_{j=0}^k {{n + j - 1}\choose{j}} p^n (1 - p)^j.\]在一系列伯努利试验中,个体成功概率为 p,这是 k 次或更少失败发生在第 n 次成功之前的概率。
- 参数:
- karray_like
允许的最大失败次数(非负整数)。
- narray_like
目标成功次数(正整数)。
- parray_like
单次事件的成功概率(浮点数)。
- outndarray, optional
函数结果的可选输出数组
- 返回:
- F标量或 ndarray
在个体成功概率为 p 的事件序列中,在 n 次成功之前发生 k 次或更少失败的概率。
另请参阅
nbdtrc负二项式生存函数
nbdtrik负二项式分位数函数
scipy.stats.nbinom负二项式分布
备注
如果为 k 或 n 传递浮点值,它们将被截断为整数。
这些项不是直接求和的;而是根据以下公式使用正则化不完全 Beta 函数,
\[\mathrm{nbdtr}(k, n, p) = I_{p}(n, k + 1).\]负二项式分布也可以通过
scipy.stats.nbinom获得。与scipy.stats.nbinom的cdf方法相比,直接使用nbdtr可以提高性能(参见最后一个示例)。参考文献
[1]Cephes 数学函数库, http://www.netlib.org/cephes/
示例
计算
k=10和n=5在p=0.5时的函数值。>>> import numpy as np >>> from scipy.special import nbdtr >>> nbdtr(10, 5, 0.5) 0.940765380859375
通过为 k 提供 NumPy 数组或列表,计算
n=10和p=0.5在多个点上的函数值。>>> nbdtr([5, 10, 15], 10, 0.5) array([0.15087891, 0.58809853, 0.88523853])
绘制四个不同参数集的函数图。
>>> import matplotlib.pyplot as plt >>> k = np.arange(130) >>> n_parameters = [20, 20, 20, 80] >>> p_parameters = [0.2, 0.5, 0.8, 0.5] >>> linestyles = ['solid', 'dashed', 'dotted', 'dashdot'] >>> parameters_list = list(zip(p_parameters, n_parameters, ... linestyles)) >>> fig, ax = plt.subplots(figsize=(8, 8)) >>> for parameter_set in parameters_list: ... p, n, style = parameter_set ... nbdtr_vals = nbdtr(k, n, p) ... ax.plot(k, nbdtr_vals, label=rf"$n={n},\, p={p}$", ... ls=style) >>> ax.legend() >>> ax.set_xlabel("$k$") >>> ax.set_title("Negative binomial cumulative distribution function") >>> plt.show()
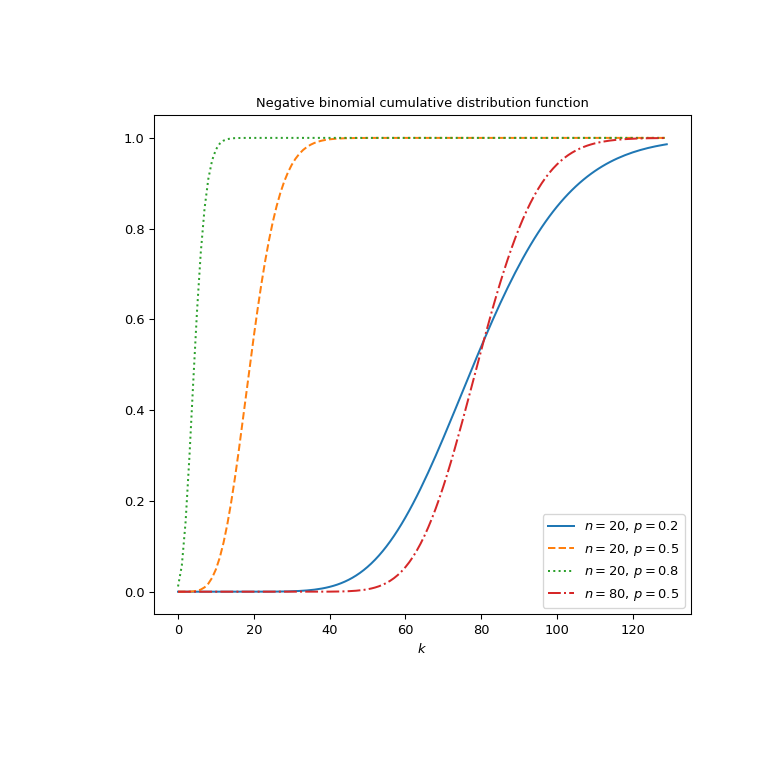
负二项式分布也可以通过
scipy.stats.nbinom获得。与调用scipy.stats.nbinom的cdf方法相比,直接使用nbdtr可以快得多,特别是对于小型数组或单个值。要获得相同的结果,必须使用以下参数化:nbinom(n, p).cdf(k)=nbdtr(k, n, p)。>>> from scipy.stats import nbinom >>> k, n, p = 5, 3, 0.5 >>> nbdtr_res = nbdtr(k, n, p) # this will often be faster than below >>> stats_res = nbinom(n, p).cdf(k) >>> stats_res, nbdtr_res # test that results are equal (0.85546875, 0.85546875)
nbdtr可以通过提供与 k、n 和 p 广播兼容形状的数组来评估不同的参数集。这里我们计算三个不同的 k 在四个 p 值处的函数,结果是一个 3x4 数组。>>> k = np.array([[5], [10], [15]]) >>> p = np.array([0.3, 0.5, 0.7, 0.9]) >>> k.shape, p.shape ((3, 1), (4,))
>>> nbdtr(k, 5, p) array([[0.15026833, 0.62304687, 0.95265101, 0.9998531 ], [0.48450894, 0.94076538, 0.99932777, 0.99999999], [0.76249222, 0.99409103, 0.99999445, 1. ]])