概率分布#
SciPy 提供了两种用于处理概率分布的基础设施。本教程介绍的是旧版基础设施,它包含许多预定义的分布;然而,新的基础设施可与其中大多数配合使用,并具有许多优点。有关新版基础设施,请参阅 随机变量迁移指南。
目前已实现了两个通用分布类,用于封装连续随机变量和离散随机变量。使用这些类已实现了 100 多个连续随机变量 (RV) 和 20 个离散随机变量。有关各个分布的数学参考信息,请参阅连续统计分布和离散统计分布。
所有统计函数都位于子包scipy.stats中,并且这些可用函数和随机变量的相当完整的列表也可以从 stats 子包的文档字符串中获取。
在下面的讨论中,我们主要关注连续随机变量。几乎所有内容也适用于离散变量,但我们在此指出一些区别:离散分布的特定要点。
在下面的代码示例中,我们假设scipy.stats包已导入为
>>> from scipy import stats
在某些情况下,我们假设单个对象导入为
>>> from scipy.stats import norm
获取帮助#
首先,所有分布都附带帮助函数。要获取一些基本信息,我们可以打印相关的文档字符串:print(stats.norm.__doc__)。
要查找分布的支持(即上限和下限),请调用
>>> print('bounds of distribution lower: %s, upper: %s' % norm.support())
bounds of distribution lower: -inf, upper: inf
我们可以使用 dir(norm) 列出分布的所有方法和属性。事实证明,有些方法是私有的,尽管它们并未如此命名(它们的名称不以_开头),例如 veccdf,仅供内部计算使用(当尝试使用这些方法时会发出警告,并将在某个时候被移除)。
要获取真正的主要方法,我们列出冻结分布的方法。(我们将在下文解释冻结分布的含义)。
>>> rv = norm()
>>> dir(rv) # reformatted
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__ge__', '__getattribute__', '__gt__', '__hash__',
'__init__', '__le__', '__lt__', '__module__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__',
'__str__', '__subclasshook__', '__weakref__', 'a', 'args', 'b', 'cdf',
'dist', 'entropy', 'expect', 'interval', 'isf', 'kwds', 'logcdf',
'logpdf', 'logpmf', 'logsf', 'mean', 'median', 'moment', 'pdf', 'pmf',
'ppf', 'random_state', 'rvs', 'sf', 'stats', 'std', 'var']
最后,我们可以通过内省获取可用分布的列表
>>> dist_continu = [d for d in dir(stats) if
... isinstance(getattr(stats, d), stats.rv_continuous)]
>>> dist_discrete = [d for d in dir(stats) if
... isinstance(getattr(stats, d), stats.rv_discrete)]
>>> print('number of continuous distributions: %d' % len(dist_continu))
number of continuous distributions: 109
>>> print('number of discrete distributions: %d' % len(dist_discrete))
number of discrete distributions: 21
常用方法#
连续随机变量的主要公共方法是
rvs: 随机变量
pdf: 概率密度函数
cdf: 累积分布函数
sf: 生存函数 (1-CDF)
ppf: 百分点函数 (CDF 的逆)
isf: 逆生存函数 (SF 的逆)
stats: 返回均值、方差、(费舍尔)偏度或(费舍尔)峰度
moment: 分布的非中心矩
让我们以一个正态随机变量为例。
>>> norm.cdf(0)
0.5
要在多个点计算 cdf,我们可以传入一个列表或一个 numpy 数组。
>>> norm.cdf([-1., 0, 1])
array([ 0.15865525, 0.5, 0.84134475])
>>> import numpy as np
>>> norm.cdf(np.array([-1., 0, 1]))
array([ 0.15865525, 0.5, 0.84134475])
因此,基本方法,例如 pdf、cdf 等,都是向量化的。
也支持其他通用的有用方法
>>> norm.mean(), norm.std(), norm.var()
(0.0, 1.0, 1.0)
>>> norm.stats(moments="mv")
(array(0.0), array(1.0))
要查找分布的中位数,我们可以使用百分点函数 ppf,它是 cdf 的逆。
>>> norm.ppf(0.5)
0.0
要生成一系列随机变量,请使用 size 关键字参数。
>>> norm.rvs(size=3)
array([-0.35687759, 1.34347647, -0.11710531]) # random
不要认为 norm.rvs(5) 会生成 5 个变量。
>>> norm.rvs(5)
5.471435163732493 # random
在这里,没有关键字的 5 被解释为第一个可能的关键字参数 loc,它是所有连续分布接受的一对关键字参数中的第一个。这引出了下一小节的主题。
随机数生成#
随机数的生成依赖于 numpy.random 包中的生成器。在上述示例中,特定的随机数流在不同运行之间是不可重现的。为了实现可重现性,您可以显式地设定种子一个随机数生成器。在 NumPy 中,生成器是 numpy.random.Generator 的一个实例。以下是创建生成器的规范方法:
>>> from numpy.random import default_rng
>>> rng = default_rng()
固定种子可以这样做:
>>> # do NOT copy this value
>>> rng = default_rng(301439351238479871608357552876690613766)
警告
不要使用这个数字或常见的数值,例如 0。仅仅使用一小组种子来实例化更大的状态空间意味着有些初始状态是无法达到的。如果每个人都使用这些值,这会产生一些偏差。获取种子的一个好方法是使用 numpy.random.SeedSequence。
>>> from numpy.random import SeedSequence
>>> print(SeedSequence().entropy)
301439351238479871608357552876690613766 # random
分布中的 random_state 参数接受 numpy.random.Generator 类的一个实例,或一个整数,该整数随后用于为内部 Generator 对象设定种子。
>>> norm.rvs(size=5, random_state=rng)
array([ 0.47143516, -1.19097569, 1.43270697, -0.3126519 , -0.72058873]) # random
更多信息请参阅 NumPy 的文档。
要了解更多关于 SciPy 中实现的随机数采样器,请参阅非均匀随机数采样教程和准蒙特卡罗教程。
平移和缩放#
所有连续分布都接受 loc 和 scale 作为关键字参数来调整分布的位置和尺度,例如,对于标准正态分布,位置是均值,尺度是标准差。
>>> norm.stats(loc=3, scale=4, moments="mv")
(array(3.0), array(16.0))
在许多情况下,随机变量 X 的标准化分布是通过转换 (X - loc) / scale 获得的。默认值为 loc = 0 和 scale = 1。
智能地使用 loc 和 scale 可以通过多种方式修改标准分布。为了进一步说明缩放,均值为 \(1/\lambda\) 的指数分布随机变量的 cdf 由下式给出:
通过应用上述缩放规则,可以看出,通过取 scale = 1./lambda,我们得到了正确的尺度。
>>> from scipy.stats import expon
>>> expon.mean(scale=3.)
3.0
注意
需要形状参数的分布可能需要不仅仅是简单地应用 loc 和/或 scale 来达到所需的形式。例如,给定一个长度为 \(R\) 的常数向量,并在每个分量中受到独立的 N(0, \(\sigma^2\)) 偏差扰动时,2D 向量长度的分布是 rice(\(R/\sigma\), scale= \(\sigma\))。第一个参数是一个形状参数,需要与 \(x\) 一起缩放。
均匀分布也很有趣
>>> from scipy.stats import uniform
>>> uniform.cdf([0, 1, 2, 3, 4, 5], loc=1, scale=4)
array([ 0. , 0. , 0.25, 0.5 , 0.75, 1. ])
最后,回想一下上一段,我们遗留了 norm.rvs(5) 含义的问题。事实证明,像这样调用分布时,第一个参数,即 5,被传递用于设置 loc 参数。让我们看看:
>>> np.mean(norm.rvs(5, size=500))
5.0098355106969992 # random
因此,为了解释上一节示例的输出:norm.rvs(5) 生成一个均值为 loc=5 的单个正态分布随机变量,因为默认的 size=1。
我们建议您显式设置 loc 和 scale 参数,通过以关键字而不是参数的形式传递值。当调用给定随机变量的多个方法时,可以通过使用冻结分布的技术来最小化重复,如下所述。
形状参数#
虽然一般的连续随机变量可以通过 loc 和 scale 参数进行平移和缩放,但有些分布需要额外的形状参数。例如,密度为的伽马分布
需要形状参数 \(a\)。请注意,设置 \(\lambda\) 可以通过将 scale 关键字设置为 \(1/\lambda\) 来获得。
让我们检查伽马分布的形状参数的数量和名称。(我们从上面知道这个值应该是 1。)
>>> from scipy.stats import gamma
>>> gamma.numargs
1
>>> gamma.shapes
'a'
现在,我们将形状变量的值设置为 1 以获得指数分布,以便我们轻松比较是否得到预期结果。
>>> gamma(1, scale=2.).stats(moments="mv")
(array(2.0), array(4.0))
请注意,我们也可以将形状参数指定为关键字。
>>> gamma(a=1, scale=2.).stats(moments="mv")
(array(2.0), array(4.0))
冻结分布#
反复传递 loc 和 scale 关键字可能会变得相当麻烦。使用冻结随机变量的概念来解决此类问题。
>>> rv = gamma(1, scale=2.)
通过使用 rv,我们不再需要包含尺度或形状参数。因此,分布可以通过两种方式使用:要么将所有分布参数传递给每个方法调用(如我们之前所做),要么冻结分布实例的参数。让我们检查一下:
>>> rv.mean(), rv.std()
(2.0, 2.0)
这确实是我们应该得到的结果。
广播#
基本方法 pdf 等都遵循通常的 numpy 广播规则。例如,我们可以计算 t 分布上尾在不同概率和自由度下的临界值。
>>> stats.t.isf([0.1, 0.05, 0.01], [[10], [11]])
array([[ 1.37218364, 1.81246112, 2.76376946],
[ 1.36343032, 1.79588482, 2.71807918]])
这里,第一行包含 10 个自由度下的临界值,第二行包含 11 个自由度(d.o.f.)下的临界值。因此,广播规则给出了两次调用 isf 相同的结果:
>>> stats.t.isf([0.1, 0.05, 0.01], 10)
array([ 1.37218364, 1.81246112, 2.76376946])
>>> stats.t.isf([0.1, 0.05, 0.01], 11)
array([ 1.36343032, 1.79588482, 2.71807918])
如果概率数组(即 [0.1, 0.05, 0.01])和自由度数组(即 [10, 11, 12])具有相同的数组形状,则使用元素匹配。例如,我们可以通过调用以下函数获得 10 个自由度下的 10% 尾部、11 个自由度下的 5% 尾部和 12 个自由度下的 1% 尾部:
>>> stats.t.isf([0.1, 0.05, 0.01], [10, 11, 12])
array([ 1.37218364, 1.79588482, 2.68099799])
离散分布的特定要点#
离散分布与连续分布基本拥有相同的基本方法。然而,pdf 被概率质量函数 pmf 取代,并且没有可用的估计方法(如拟合),同时 scale 不是一个有效的关键字参数。位置参数,关键字 loc,仍然可以用于平移分布。
cdf 的计算需要额外注意。在连续分布的情况下,累积分布函数在大多数标准情况下,在区间 (a,b) 内是严格单调递增的,因此具有唯一的逆函数。然而,离散分布的 cdf 是一个阶梯函数,因此逆 cdf,即百分点函数,需要不同的定义。
ppf(q) = min{x : cdf(x) >= q, x integer}
更多信息请参阅此处的文档。
我们可以将超几何分布作为一个例子。
>>> from scipy.stats import hypergeom
>>> [M, n, N] = [20, 7, 12]
如果我们使用 cdf 在某些整数点上的值,然后根据这些 cdf 值计算 ppf,我们将得到原始整数,例如:
>>> x = np.arange(4) * 2
>>> x
array([0, 2, 4, 6])
>>> prb = hypergeom.cdf(x, M, n, N)
>>> prb
array([ 1.03199174e-04, 5.21155831e-02, 6.08359133e-01,
9.89783282e-01])
>>> hypergeom.ppf(prb, M, n, N)
array([ 0., 2., 4., 6.])
如果我们使用的值不在 cdf 阶梯函数的拐点上,我们将得到下一个更高的整数。
>>> hypergeom.ppf(prb + 1e-8, M, n, N)
array([ 1., 3., 5., 7.])
>>> hypergeom.ppf(prb - 1e-8, M, n, N)
array([ 0., 2., 4., 6.])
拟合分布#
未冻结分布的主要附加方法与分布参数的估计有关:
- fit: 分布参数的最大似然估计,包括位置
和尺度
fit_loc_scale: 在给定形状参数时估计位置和尺度
nnlf: 负对数似然函数
expect: 计算函数相对于 pdf 或 pmf 的期望值
性能问题和注意事项#
单个方法的性能(在速度方面)因分布和方法而异。方法的计算结果有两种获取方式:要么通过显式计算,要么通过独立于特定分布的通用算法。
显式计算一方面要求该方法直接为给定分布指定,无论是通过解析公式还是通过 scipy.special 或 numpy.random 中的特殊函数来计算 rvs。这些通常是相对较快的计算。
另一方面,如果分布未指定任何显式计算,则使用通用方法。要定义一个分布,只需要 pdf 或 cdf 中的一个;所有其他方法都可以通过数值积分和求根导出。然而,这些间接方法可能非常慢。例如,rgh = stats.gausshyper.rvs(0.5, 2, 2, 2, size=100) 以一种非常间接的方式创建随机变量,在我的电脑上为 100 个随机变量需要大约 19 秒,而从标准正态分布或 t 分布中生成一百万个随机变量只需要略多于一秒。
遗留问题#
scipy.stats 中的分布最近得到了修正和改进,并增加了一个相当大的测试套件;然而,仍存在一些问题:
这些分布已在一定的参数范围内进行了测试;然而,在某些极端范围内,可能仍存在一些不正确的结果。
fit 中的最大似然估计不适用于所有分布的默认起始参数,用户需要提供良好的起始参数。此外,对于某些分布,使用最大似然估计器本身可能不是最佳选择。
构建特定分布#
接下来的示例将展示如何构建您自己的分布。其他示例将展示分布的使用和一些统计检验。
创建连续分布,即继承 rv_continuous#
创建连续分布相当简单。
>>> from scipy import stats
>>> class deterministic_gen(stats.rv_continuous):
... def _cdf(self, x):
... return np.where(x < 0, 0., 1.)
... def _stats(self):
... return 0., 0., 0., 0.
>>> deterministic = deterministic_gen(name="deterministic")
>>> deterministic.cdf(np.arange(-3, 3, 0.5))
array([ 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1.])
有趣的是,pdf 现在是自动计算的。
>>> deterministic.pdf(np.arange(-3, 3, 0.5))
array([ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
5.83333333e+04, 4.16333634e-12, 4.16333634e-12,
4.16333634e-12, 4.16333634e-12, 4.16333634e-12])
请注意性能问题和注意事项中提到的性能问题。未指定通用方法的计算可能会变得非常慢,因为只调用通用方法,这些方法本质上不能使用关于分布的任何特定信息。因此,作为一个警示性示例:
>>> from scipy.integrate import quad
>>> quad(deterministic.pdf, -1e-1, 1e-1)
(4.163336342344337e-13, 0.0)
但这不正确:该 pdf 的积分应为 1。让我们缩小积分区间:
>>> quad(deterministic.pdf, -1e-3, 1e-3) # warning removed
(1.000076872229173, 0.0010625571718182458)
这看起来好多了。然而,问题源于确定性分布的类定义中没有指定 pdf。
继承 rv_discrete#
在下文中,我们使用 stats.rv_discrete 生成一个离散分布,该分布在以整数为中心的区间内具有截断正态分布的概率。
一般信息
从 rv_discrete 的文档字符串 help(stats.rv_discrete) 中:
“您可以通过向 rv_discrete 初始化方法(通过 values= 关键字)传递一个序列元组 (xk, pk) 来构造任意离散随机变量,其中 P{X=xk} = pk,该元组仅描述 X 的那些非零概率值 (xk)。”
除此之外,这种方法还需要一些额外的要求才能奏效:
关键字 name 是必需的。
分布的支持点 xk 必须是整数。
需要指定有效位数(小数位)。
实际上,如果后两个要求未满足,可能会引发异常或导致结果不正确。
一个例子
我们来动手。首先:
>>> npoints = 20 # number of integer support points of the distribution minus 1
>>> npointsh = npoints // 2
>>> npointsf = float(npoints)
>>> nbound = 4 # bounds for the truncated normal
>>> normbound = (1+1/npointsf) * nbound # actual bounds of truncated normal
>>> grid = np.arange(-npointsh, npointsh+2, 1) # integer grid
>>> gridlimitsnorm = (grid-0.5) / npointsh * nbound # bin limits for the truncnorm
>>> gridlimits = grid - 0.5 # used later in the analysis
>>> grid = grid[:-1]
>>> probs = np.diff(stats.truncnorm.cdf(gridlimitsnorm, -normbound, normbound))
>>> gridint = grid
最后,我们可以继承 rv_discrete。
>>> normdiscrete = stats.rv_discrete(values=(gridint,
... np.round(probs, decimals=7)), name='normdiscrete')
现在我们已经定义了分布,我们可以访问离散分布的所有常用方法。
>>> print('mean = %6.4f, variance = %6.4f, skew = %6.4f, kurtosis = %6.4f' %
... normdiscrete.stats(moments='mvsk'))
mean = -0.0000, variance = 6.3302, skew = 0.0000, kurtosis = -0.0076
>>> nd_std = np.sqrt(normdiscrete.stats(moments='v'))
测试实现
我们生成一个随机样本,并将观测频率与概率进行比较。
>>> n_sample = 500
>>> rvs = normdiscrete.rvs(size=n_sample)
>>> f, l = np.histogram(rvs, bins=gridlimits)
>>> sfreq = np.vstack([gridint, f, probs*n_sample]).T
>>> print(sfreq)
[[-1.00000000e+01 0.00000000e+00 2.95019349e-02] # random
[-9.00000000e+00 0.00000000e+00 1.32294142e-01]
[-8.00000000e+00 0.00000000e+00 5.06497902e-01]
[-7.00000000e+00 2.00000000e+00 1.65568919e+00]
[-6.00000000e+00 1.00000000e+00 4.62125309e+00]
[-5.00000000e+00 9.00000000e+00 1.10137298e+01]
[-4.00000000e+00 2.60000000e+01 2.24137683e+01]
[-3.00000000e+00 3.70000000e+01 3.89503370e+01]
[-2.00000000e+00 5.10000000e+01 5.78004747e+01]
[-1.00000000e+00 7.10000000e+01 7.32455414e+01]
[ 0.00000000e+00 7.40000000e+01 7.92618251e+01]
[ 1.00000000e+00 8.90000000e+01 7.32455414e+01]
[ 2.00000000e+00 5.50000000e+01 5.78004747e+01]
[ 3.00000000e+00 5.00000000e+01 3.89503370e+01]
[ 4.00000000e+00 1.70000000e+01 2.24137683e+01]
[ 5.00000000e+00 1.10000000e+01 1.10137298e+01]
[ 6.00000000e+00 4.00000000e+00 4.62125309e+00]
[ 7.00000000e+00 3.00000000e+00 1.65568919e+00]
[ 8.00000000e+00 0.00000000e+00 5.06497902e-01]
[ 9.00000000e+00 0.00000000e+00 1.32294142e-01]
[ 1.00000000e+01 0.00000000e+00 2.95019349e-02]]
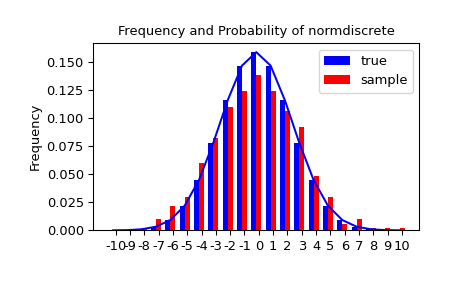
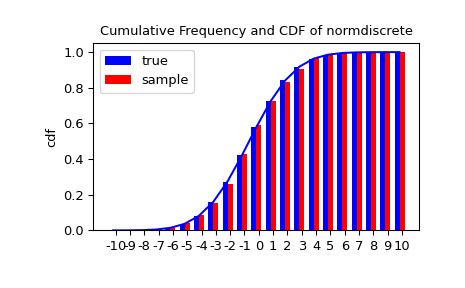
接下来,我们可以使用卡方检验 scipy.stats.chisquare 来检验样本是否按照我们的正态离散分布的零假设。
该检验要求每个区间(bin)中至少有一定数量的观测值。我们将尾部区间合并到更大的区间中,以便它们包含足够的观测值。
>>> f2 = np.hstack([f[:5].sum(), f[5:-5], f[-5:].sum()])
>>> p2 = np.hstack([probs[:5].sum(), probs[5:-5], probs[-5:].sum()])
>>> ch2, pval = stats.chisquare(f2, p2*n_sample)
>>> print('chisquare for normdiscrete: chi2 = %6.3f pvalue = %6.4f' % (ch2, pval))
chisquare for normdiscrete: chi2 = 12.466 pvalue = 0.4090 # random
从概念上讲,检验统计量 chi2 对观测频率与零假设下的预期频率之间的偏差很敏感。p 值是从假设分布中抽取样本,从而产生比我们观测到的更极端统计值的概率。我们的统计值并不高;实际上,如果我们从 p2 定义的离散分布中抽取相同大小的样本,统计值高于 12.466 的可能性为 40.9%。因此,该检验几乎没有证据反对样本是从我们的正态离散分布中抽取的零假设。