logrank#
- scipy.stats.logrank(x, y, alternative='two-sided')[source]#
通过 logrank 检验比较两个样本的生存分布。
- 参数:
- x, y类数组 或 CensoredData
基于经验生存函数进行比较的样本。
- alternative{‘two-sided’, ‘less’, ‘greater’}, 可选
定义备择假设。
零假设是两组(比如 *X* 和 *Y*)的生存分布相同。
以下备择假设 [4] 可用 (默认为 ‘two-sided’)
‘two-sided’: 两组的生存分布不相同。
‘less’: 组 *X* 的生存更有利:组 *X* 的失败率函数在某些时候小于组 *Y* 的失败率函数。
‘greater’: 组 *Y* 的生存更有利:组 *X* 的失败率函数在某些时候大于组 *Y* 的失败率函数。
- 返回值:
- resLogRankResult
包含属性的对象
- statisticfloat ndarray
计算的统计量(定义如下)。其幅度是大多数其他 logrank 检验实现返回的幅度的平方根。
- pvaluefloat ndarray
检验的计算出的 p 值。
注释
logrank 检验 [1] 将观察到的事件数与零假设下(两个样本来自同一分布)的预期事件数进行比较。统计量为
\[Z_i = \frac{\sum_{j=1}^J(O_{i,j}-E_{i,j})}{\sqrt{\sum_{j=1}^J V_{i,j}}} \rightarrow \mathcal{N}(0,1)\]其中
\[E_{i,j} = O_j \frac{N_{i,j}}{N_j}, \qquad V_{i,j} = E_{i,j} \left(\frac{N_j-O_j}{N_j}\right) \left(\frac{N_j-N_{i,j}}{N_j-1}\right),\]\(i\) 表示组 (即,它可以假定值 \(x\) 或 \(y\),或者可以省略以指代组合样本) \(j\) 表示时间 (事件发生的时间),\(N\) 是事件发生前处于危险中的受试者人数,而 \(O\) 是该时间观察到的事件数。
statistic\(Z_x\) 由logrank返回,是许多其他实现返回的统计量的(带符号的)平方根。在零假设下,\(Z_x**2\) 渐近地按照具有一个自由度的卡方分布分布。因此,\(Z_x\) 渐近地按照标准正态分布分布。使用 \(Z_x\) 的优点是保留了符号信息(即,观察到的事件数是否往往小于或大于零假设下的预期数字),从而允许scipy.stats.logrank提供单侧备择假设。参考文献
[1]Mantel N. “Evaluation of survival data and two new rank order statistics arising in its consideration.” Cancer Chemotherapy Reports, 50(3):163-170, PMID: 5910392, 1966
[2]Bland, Altman, “The logrank test”, BMJ, 328:1073, DOI:10.1136/bmj.328.7447.1073, 2004
[3]“Logrank test”, Wikipedia, https://en.wikipedia.org/wiki/Logrank_test
[4]Brown, Mark. “On the choice of variance for the log rank test.” Biometrika 71.1 (1984): 65-74.
[5]Klein, John P., and Melvin L. Moeschberger. Survival analysis: techniques for censored and truncated data. Vol. 1230. New York: Springer, 2003.
示例
参考文献 [2] 比较了两种不同类型复发性恶性神经胶质瘤患者的生存时间。下面的样本记录了每位患者参与研究的时间(周数)。使用
scipy.stats.CensoredData类是因为数据是右删失的:未删失的观察结果对应于观察到的死亡,而删失的观察结果对应于患者因其他原因离开研究。>>> from scipy import stats >>> x = stats.CensoredData( ... uncensored=[6, 13, 21, 30, 37, 38, 49, 50, ... 63, 79, 86, 98, 202, 219], ... right=[31, 47, 80, 82, 82, 149] ... ) >>> y = stats.CensoredData( ... uncensored=[10, 10, 12, 13, 14, 15, 16, 17, 18, 20, 24, 24, ... 25, 28,30, 33, 35, 37, 40, 40, 46, 48, 76, 81, ... 82, 91, 112, 181], ... right=[34, 40, 70] ... )
我们可以按如下方式计算和可视化两组的经验生存函数。
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> ax = plt.subplot() >>> ecdf_x = stats.ecdf(x) >>> ecdf_x.sf.plot(ax, label='Astrocytoma') >>> ecdf_y = stats.ecdf(y) >>> ecdf_y.sf.plot(ax, label='Glioblastoma') >>> ax.set_xlabel('Time to death (weeks)') >>> ax.set_ylabel('Empirical SF') >>> plt.legend() >>> plt.show()
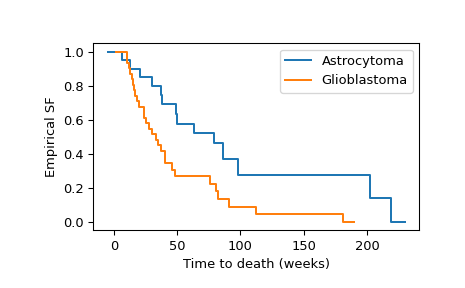
对经验生存函数的目视检查表明,两组之间的生存时间往往不同。为了正式评估差异是否在 1% 的水平上显着,我们使用 logrank 检验。
>>> res = stats.logrank(x=x, y=y) >>> res.statistic -2.73799 >>> res.pvalue 0.00618
p 值小于 1%,因此我们可以认为该数据是反对零假设的证据,有利于两种生存函数之间存在差异的替代假设。