峰度#
- scipy.stats.kurtosis(a, axis=0, fisher=True, bias=True, nan_policy='propagate', *, keepdims=False)[source]#
计算数据集的峰度(Fisher 或 Pearson)。
峰度是第四个中心矩除以方差的平方。如果使用 Fisher 的定义,则从结果中减去 3.0,使正态分布的峰度为 0.0。
如果 bias 为 False,则使用 k 统计量计算峰度,以消除来自有偏矩估计量的偏差
使用
kurtosistest来查看结果是否足够接近正态分布。- 参数:
- a数组
计算峰度的数据。
- axisint 或 None,默认值:0
如果为 int,则为沿其计算统计量的输入轴。输入的每个轴切片(例如,行)的统计量将显示在输出的相应元素中。如果为
None,则在计算统计量之前将输入展开。- fisherbool,可选
如果为 True,则使用 Fisher 的定义(normal ==> 0.0)。如果为 False,则使用 Pearson 的定义(normal ==> 3.0)。
- biasbool,可选
如果为 False,则计算结果将针对统计偏差进行校正。
- nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入 NaN。
propagate:如果在沿其计算统计量的轴切片(例如,行)中存在 NaN,则输出的相应条目将为 NaN。omit:执行计算时将忽略 NaN。如果在沿其计算统计量的轴切片中剩余的数据不足,则输出的相应条目将为 NaN。raise:如果存在 NaN,则将引发ValueError。
- keepdimsbool,默认值:False
如果将其设置为 True,则减小的轴将保留在结果中,作为大小为 1 的维度。使用此选项,结果将正确地广播到输入数组。
- 返回:
- 峰度数组
沿轴的值的峰度,如果所有值都相等,则返回 NaN。
注释
从 SciPy 1.9 开始,
np.matrix输入(不推荐用于新代码)在执行计算之前会转换为np.ndarray。在这种情况下,输出将是标量或适当形状的np.ndarray,而不是 2Dnp.matrix。类似地,虽然会忽略 masked 数组的 masked 元素,但输出将是标量或np.ndarray,而不是mask=False的 masked 数组。kurtosis除了 NumPy 之外,还对 Python Array API Standard 兼容后端提供实验性支持。请考虑通过设置环境变量SCIPY_ARRAY_API=1并提供 CuPy、PyTorch、JAX 或 Dask 数组作为数组参数来测试这些功能。支持以下后端和设备(或其他功能)的组合。库
CPU
GPU
NumPy
✅
不适用
CuPy
不适用
✅
PyTorch
✅
✅
JAX
⚠️ 无 JIT
⚠️ 无 JIT
Dask
⚠️ 计算图
不适用
有关更多信息,请参阅 对数组 API 标准的支持。
参考文献
[1]Zwillinger, D. 和 Kokoska, S. (2000)。CRC 标准概率和统计表和公式。Chapman & Hall:纽约。2000。
示例
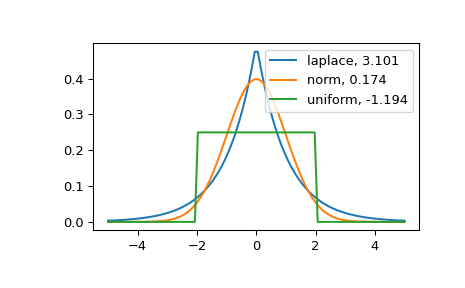
在 Fisher 的定义中,正态分布的峰度为零。在以下示例中,峰度接近于零,因为它是由数据集计算得出,而不是由连续分布计算得出。
>>> import numpy as np >>> from scipy.stats import norm, kurtosis >>> data = norm.rvs(size=1000, random_state=3) >>> kurtosis(data) -0.06928694200380558
具有较高峰度的分布具有较重的尾部。Fisher 定义中正态分布的零值峰度可以用作参考点。
>>> import matplotlib.pyplot as plt >>> import scipy.stats as stats >>> from scipy.stats import kurtosis
>>> x = np.linspace(-5, 5, 100) >>> ax = plt.subplot() >>> distnames = ['laplace', 'norm', 'uniform']
>>> for distname in distnames: ... if distname == 'uniform': ... dist = getattr(stats, distname)(loc=-2, scale=4) ... else: ... dist = getattr(stats, distname) ... data = dist.rvs(size=1000) ... kur = kurtosis(data, fisher=True) ... y = dist.pdf(x) ... ax.plot(x, y, label="{}, {}".format(distname, round(kur, 3))) ... ax.legend()
拉普拉斯分布比正态分布具有更重的尾部。均匀分布(具有负峰度)具有最薄的尾部。