binned_statistic#
- scipy.stats.binned_statistic(x, values, statistic='mean', bins=10, range=None)[source]#
计算一个或多个数据集的箱体统计量。
这是直方图函数的一个推广。直方图将空间划分为多个箱体,并返回每个箱体中点的数量。此函数允许计算每个箱体中值的总和、平均值、中位数或其他统计量(或一组值)。
- 参数:
- x(N,) 类似数组
要放入箱体中的值的序列。
- values(N,) 类似数组或 (N,) 类似数组的列表
将在其上计算统计量的数据。这必须与 x 的形状相同,或是一组序列 - 每个序列与 x 的形状相同。如果 values 是一组序列,则将独立计算每个序列的统计量。
- statistic字符串或可调用对象,可选
要计算的统计量(默认为 'mean')。以下统计量可用
'mean':计算每个箱体内点的值的平均值。空箱体将由 NaN 表示。
'std':计算每个箱体内的标准差。这是隐式地用 ddof=0 计算的。
'median':计算每个箱体内点的中位数。空箱体将由 NaN 表示。
'count':计算每个箱体内点的数量。这与未加权的直方图相同。values 数组未被引用。
'sum':计算每个箱体内点的值的总和。这与加权直方图相同。
'min':计算每个箱体内点的最小值。空箱体将由 NaN 表示。
'max':计算每个箱体内点的最大值。空箱体将由 NaN 表示。
function:一个用户定义的函数,它接受一个一维值数组,并输出一个单一的数值统计量。该函数将在每个箱体中的值上调用。空箱体将由 function([]) 表示,如果这返回错误,则由 NaN 表示。
- bins整数或标量序列,可选
如果 bins 是一个整数,它定义了给定范围内的等宽箱体的数量(默认为 10)。如果 bins 是一个序列,它定义了箱体的边缘,包括最右边的边缘,允许非均匀的箱体宽度。x 中小于最低箱体边缘的值将被分配到箱体编号 0,超出最高箱体的值将被分配到
bins[-1]。如果指定了箱体边缘,则箱体的数量将为 (nx = len(bins)-1)。- range(浮点数, 浮点数) 或 [(浮点数, 浮点数)], 可选
箱体的下限和上限范围。如果未提供,则范围只是
(x.min(), x.max())。范围之外的值将被忽略。
- 返回:
- statistic数组
每个箱体中选定统计量的值。
- bin_edges浮点数类型的数组
返回箱体边缘
(length(statistic)+1)。- binnumber: 整数的 1-D ndarray
每个 x 值所属的箱体的索引(对应于 bin_edges)。与 values 长度相同。i 的箱体编号表示对应的值位于 (bin_edges[i-1], bin_edges[i]) 之间。
注释
除了最后一个(最右边)箱体之外,所有箱体都是半开的。换句话说,如果 bins 是
[1, 2, 3, 4],那么第一个箱体是[1, 2)(包括 1,但不包括 2),第二个箱体是[2, 3)。然而,最后一个箱体是[3, 4],它包括 4。在 0.11.0 版本中添加。
示例
>>> import numpy as np >>> from scipy import stats >>> import matplotlib.pyplot as plt
首先是一些基本示例
在给定样本的范围内创建两个均匀间隔的箱体,并对每个箱体中的相应值求和
>>> values = [1.0, 1.0, 2.0, 1.5, 3.0] >>> stats.binned_statistic([1, 1, 2, 5, 7], values, 'sum', bins=2) BinnedStatisticResult(statistic=array([4. , 4.5]), bin_edges=array([1., 4., 7.]), binnumber=array([1, 1, 1, 2, 2]))
也可以传递多个值数组。统计量是在每个集合上独立计算的
>>> values = [[1.0, 1.0, 2.0, 1.5, 3.0], [2.0, 2.0, 4.0, 3.0, 6.0]] >>> stats.binned_statistic([1, 1, 2, 5, 7], values, 'sum', bins=2) BinnedStatisticResult(statistic=array([[4. , 4.5], [8. , 9. ]]), bin_edges=array([1., 4., 7.]), binnumber=array([1, 1, 1, 2, 2]))
>>> stats.binned_statistic([1, 2, 1, 2, 4], np.arange(5), statistic='mean', ... bins=3) BinnedStatisticResult(statistic=array([1., 2., 4.]), bin_edges=array([1., 2., 3., 4.]), binnumber=array([1, 2, 1, 2, 3]))
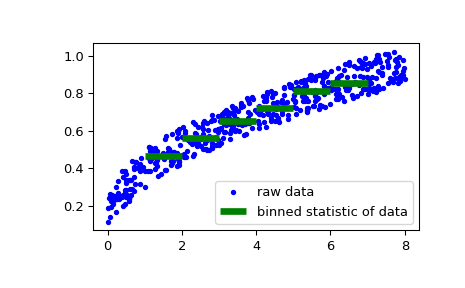
作为第二个例子,我们现在生成一些帆船速度作为风速函数的随机数据,然后确定我们的船在某些风速下的速度
>>> rng = np.random.default_rng() >>> windspeed = 8 * rng.random(500) >>> boatspeed = .3 * windspeed**.5 + .2 * rng.random(500) >>> bin_means, bin_edges, binnumber = stats.binned_statistic(windspeed, ... boatspeed, statistic='median', bins=[1,2,3,4,5,6,7]) >>> plt.figure() >>> plt.plot(windspeed, boatspeed, 'b.', label='raw data') >>> plt.hlines(bin_means, bin_edges[:-1], bin_edges[1:], colors='g', lw=5, ... label='binned statistic of data') >>> plt.legend()
现在我们可以使用
binnumber选择所有风速低于 1 的数据点>>> low_boatspeed = boatspeed[binnumber == 0]
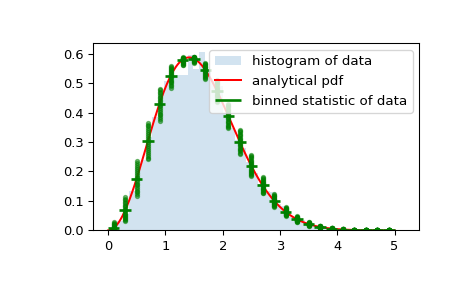
作为最后一个例子,我们将使用
bin_edges和binnumber绘制一个分布图,该分布图显示每个箱体的平均值和平均值周围的分布,并在常规直方图和概率分布函数之上显示>>> x = np.linspace(0, 5, num=500) >>> x_pdf = stats.maxwell.pdf(x) >>> samples = stats.maxwell.rvs(size=10000)
>>> bin_means, bin_edges, binnumber = stats.binned_statistic(x, x_pdf, ... statistic='mean', bins=25) >>> bin_width = (bin_edges[1] - bin_edges[0]) >>> bin_centers = bin_edges[1:] - bin_width/2
>>> plt.figure() >>> plt.hist(samples, bins=50, density=True, histtype='stepfilled', ... alpha=0.2, label='histogram of data') >>> plt.plot(x, x_pdf, 'r-', label='analytical pdf') >>> plt.hlines(bin_means, bin_edges[:-1], bin_edges[1:], colors='g', lw=2, ... label='binned statistic of data') >>> plt.plot((binnumber - 0.5) * bin_width, x_pdf, 'g.', alpha=0.5) >>> plt.legend(fontsize=10) >>> plt.show()