多维图像处理 (scipy.ndimage)#
介绍#
图像处理和分析通常被视为对二维数值数组的操作。然而,在许多领域,需要分析更高维度的图像。医学成像和生物成像就是很好的例子。 numpy 非常适合这种类型的应用,因为它具有固有的多维特性。 scipy.ndimage 包提供了一些通用的图像处理和分析函数,这些函数旨在与任意维度的数组一起使用。该包目前包括:用于线性滤波和非线性滤波、二值形态学、B 样条插值和对象测量的函数。
滤波函数#
本节中描述的函数都执行某种类型的输入数组的空间滤波:输出中的元素是对应输入元素邻域中值的某个函数。我们将此元素邻域称为滤波器核,它通常呈矩形形状,但也可能具有任意形状。下面描述的许多函数允许您通过 footprint 参数传递掩码来定义核的形状。例如,十字形核可以定义如下
>>> footprint = np.array([[0, 1, 0], [1, 1, 1], [0, 1, 0]])
>>> footprint
array([[0, 1, 0],
[1, 1, 1],
[0, 1, 0]])
通常,核的原点位于通过将核形状的维度除以二计算的中心。例如,长度为三的一维核的原点位于第二个元素。例如,一维数组与长度为 3 的滤波器(由 1 组成)的相关性
>>> from scipy.ndimage import correlate1d
>>> a = [0, 0, 0, 1, 0, 0, 0]
>>> correlate1d(a, [1, 1, 1])
array([0, 0, 1, 1, 1, 0, 0])
有时,选择核的不同原点很方便。为此,大多数函数支持 origin 参数,该参数给出滤波器相对于其中心的原点。例如
>>> a = [0, 0, 0, 1, 0, 0, 0]
>>> correlate1d(a, [1, 1, 1], origin = -1)
array([0, 1, 1, 1, 0, 0, 0])
效果是将结果向左移动。此功能不会经常使用,但可能有用,尤其是对于大小为偶数的滤波器。一个很好的例子是计算前向和后向差分。
>>> a = [0, 0, 1, 1, 1, 0, 0]
>>> correlate1d(a, [-1, 1]) # backward difference
array([ 0, 0, 1, 0, 0, -1, 0])
>>> correlate1d(a, [-1, 1], origin = -1) # forward difference
array([ 0, 1, 0, 0, -1, 0, 0])
我们也可以按如下方式计算前向差分
>>> correlate1d(a, [0, -1, 1])
array([ 0, 1, 0, 0, -1, 0, 0])
但是,使用 origin 参数而不是更大的内核更有效。对于多维内核,origin 可以是数字,在这种情况下,假设 origin 沿所有轴相等,或者是一个序列,给出沿每个轴的 origin。
由于输出元素是输入元素邻域中元素的函数,因此需要通过提供边界之外的值来适当地处理数组的边界。这是通过假设数组根据某些边界条件扩展到其边界之外来完成的。在下面描述的函数中,可以使用 mode 参数选择边界条件,该参数必须是包含边界条件名称的字符串。目前支持以下边界条件
mode
描述
示例
“nearest”
使用边界处的数值
[1 2 3]->[1 1 2 3 3]
“wrap”
周期性地复制数组
[1 2 3]->[3 1 2 3 1]
“reflect”
在边界处反射数组
[1 2 3]->[1 1 2 3 3]
“mirror”
在边界处镜像数组
[1 2 3]->[2 1 2 3 2]
“constant”
使用常数值,默认值为 0.0
[1 2 3]->[0 1 2 3 0]
为了与插值例程保持一致,还支持以下同义词
mode
描述
“grid-constant”
等效于“constant”*
“grid-mirror”
等效于“reflect”
“grid-wrap”
等效于“wrap”
* “grid-constant” 和 “constant” 在过滤操作中是等效的,但在插值函数中具有不同的行为。为了 API 一致性,过滤函数接受任一名称。
“constant” 模式很特殊,因为它需要一个额外的参数来指定要使用的常数值。
请注意,模式 mirror 和 reflect 仅在边界处的样本在反射时是否重复方面有所不同。对于模式 mirror,对称点正好位于最后一个样本处,因此该值不会重复。此模式也称为全样本对称,因为对称点落在最后一个样本上。类似地,reflect 通常被称为半样本对称,因为对称点位于数组边界之外的半个样本处。
注意
实现此类边界条件的最简单方法是将数据复制到更大的数组中,并根据边界条件扩展边界处的数据。对于大型数组和大型滤波器内核,这将非常消耗内存,因此,下面描述的函数使用不同的方法,不需要分配大型临时缓冲区。
相关和卷积#
该
correlate1d函数计算沿给定轴的 1-D 相关性。数组沿给定轴的各行与给定的 weights 相关。weights 参数必须是数字的 1-D 序列。该函数
correlate实现输入数组与给定内核的多维相关性。该
convolve1d函数计算沿给定轴的 1-D 卷积。数组沿给定轴的各行与给定的 weights 卷积。weights 参数必须是数字的 1-D 序列。该函数
convolve实现输入数组与给定内核的多维卷积。注意
卷积本质上是在镜像内核后的相关性。因此,origin 参数的行为与相关性情况不同:结果向相反方向移动。
平滑滤波器#
该
gaussian_filter1d函数实现 1-D 高斯滤波器。高斯滤波器的标准差通过参数 sigma 传递。设置 order = 0 对应于与高斯内核的卷积。1、2 或 3 的阶数对应于与高斯的一阶、二阶或三阶导数的卷积。未实现更高阶导数。函数
gaussian_filter实现了一个多维高斯滤波器。高斯滤波器沿每个轴的标准差通过参数 sigma 作为序列或数字传递。如果 sigma 不是序列而是一个数字,则滤波器的标准差沿所有方向相等。滤波器的阶数可以针对每个轴单独指定。阶数为 0 对应于与高斯核的卷积。阶数为 1、2 或 3 对应于与高斯的一阶、二阶或三阶导数的卷积。未实现更高阶导数。order 参数必须是一个数字,用于指定所有轴的相同阶数,或者是一个数字序列,用于指定每个轴的不同阶数。下面的示例显示了将滤波器应用于具有不同 sigma 值的测试数据。order 参数保持为 0。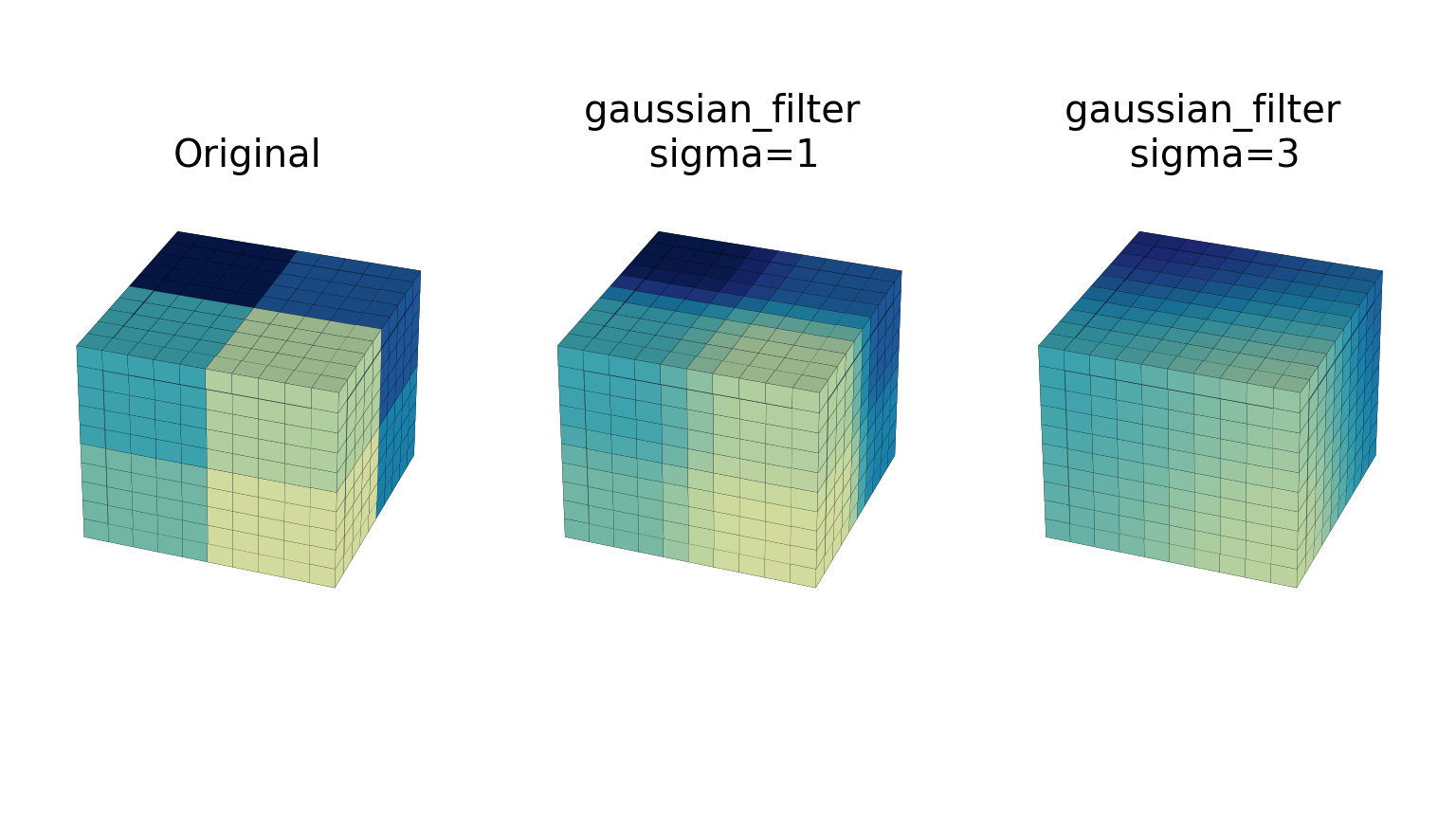
注意
多维滤波器实现为一系列一维高斯滤波器。中间数组存储在与输出相同的数据类型中。因此,对于精度较低的输出类型,结果可能不精确,因为中间结果可能以精度不足的方式存储。这可以通过指定更精确的输出类型来防止。
函数
uniform_filter1d计算给定 size 沿给定轴的一维均匀滤波器。函数
uniform_filter实现了一个多维均匀滤波器。均匀滤波器的尺寸由参数 size 作为整数序列为每个轴给出。如果 size 不是序列,而是一个数字,则假设所有轴的尺寸都相等。注意
多维滤波器实现为一系列一维均匀滤波器。中间数组存储在与输出相同的数据类型中。因此,对于精度较低的输出类型,结果可能不精确,因为中间结果可能以精度不足的方式存储。这可以通过指定更精确的输出类型来防止。
基于顺序统计的滤波器#
minimum_filter1d函数计算给定轴上给定size的1-D最小值滤波器。maximum_filter1d函数计算给定轴上给定size的1-D最大值滤波器。minimum_filter函数计算多维最小值滤波器。必须提供矩形内核的大小或内核的足迹。如果提供size参数,则它必须是大小序列或单个数字,在这种情况下,滤波器的大小被假定为沿每个轴相等。如果提供footprint,则它必须是一个数组,通过其非零元素定义内核的形状。maximum_filter函数计算多维最大值滤波器。必须提供矩形内核的大小或内核的足迹。如果提供size参数,则它必须是大小序列或单个数字,在这种情况下,滤波器的大小被假定为沿每个轴相等。如果提供footprint,则它必须是一个数组,通过其非零元素定义内核的形状。rank_filter函数计算多维排序滤波器。rank 可以小于零,例如,rank = -1 表示最大元素。必须提供矩形内核的大小或内核的足迹。如果提供了 size 参数,则它必须是大小序列或单个数字,在这种情况下,假定滤波器的大小沿每个轴相等。如果提供了 footprint,则它必须是一个数组,通过其非零元素定义内核的形状。percentile_filter函数计算多维百分位数滤波器。percentile 可以小于零,例如,percentile = -20 等于 percentile = 80。必须提供矩形内核的大小或内核的足迹。如果提供了 size 参数,则它必须是大小序列或单个数字,在这种情况下,假定滤波器的大小沿每个轴相等。如果提供了 footprint,则它必须是一个数组,通过其非零元素定义内核的形状。median_filter函数计算多维中值滤波器。必须提供矩形内核的大小或内核的足迹。如果提供了 size 参数,则它必须是大小序列或单个数字,在这种情况下,假定滤波器的大小沿每个轴相等。如果提供了 footprint,则它必须是一个数组,通过其非零元素定义内核的形状。
导数#
导数滤波器可以通过多种方式构建。函数 gaussian_filter1d(在 平滑滤波器 中描述)可用于使用 order 参数计算沿给定轴的导数。其他导数滤波器是 Prewitt 和 Sobel 滤波器
拉普拉斯滤波器通过所有轴上的二阶导数之和来计算。因此,可以使用不同的二阶导数函数构建不同的拉普拉斯滤波器。因此,我们提供了一个通用函数,该函数接受一个函数参数来计算给定方向上的二阶导数。
函数
generic_laplace使用通过derivative2传递的函数来计算拉普拉斯滤波器,以计算二阶导数。函数derivative2应具有以下签名derivative2(input, axis, output, mode, cval, *extra_arguments, **extra_keywords)
它应该计算沿维度 axis 的二阶导数。如果 output 不是
None,它应该使用它作为输出并返回None,否则它应该返回结果。mode、cval 具有通常的含义。extra_arguments 和 extra_keywords 参数可用于传递一个额外的参数元组和一个命名参数字典,这些参数和字典在每次调用时传递给
derivative2。例如
>>> def d2(input, axis, output, mode, cval): ... return correlate1d(input, [1, -2, 1], axis, output, mode, cval, 0) ... >>> a = np.zeros((5, 5)) >>> a[2, 2] = 1 >>> from scipy.ndimage import generic_laplace >>> generic_laplace(a, d2) array([[ 0., 0., 0., 0., 0.], [ 0., 0., 1., 0., 0.], [ 0., 1., -4., 1., 0.], [ 0., 0., 1., 0., 0.], [ 0., 0., 0., 0., 0.]])
为了演示 extra_arguments 参数的使用,我们可以执行以下操作
>>> def d2(input, axis, output, mode, cval, weights): ... return correlate1d(input, weights, axis, output, mode, cval, 0,) ... >>> a = np.zeros((5, 5)) >>> a[2, 2] = 1 >>> generic_laplace(a, d2, extra_arguments = ([1, -2, 1],)) array([[ 0., 0., 0., 0., 0.], [ 0., 0., 1., 0., 0.], [ 0., 1., -4., 1., 0.], [ 0., 0., 1., 0., 0.], [ 0., 0., 0., 0., 0.]])
或者
>>> generic_laplace(a, d2, extra_keywords = {'weights': [1, -2, 1]}) array([[ 0., 0., 0., 0., 0.], [ 0., 0., 1., 0., 0.], [ 0., 1., -4., 1., 0.], [ 0., 0., 1., 0., 0.], [ 0., 0., 0., 0., 0.]])
以下两个函数是使用 generic_laplace 实现的,方法是为二阶导数函数提供适当的函数
函数
laplace使用离散微分来计算拉普拉斯,用于二阶导数(即,与[1, -2, 1]进行卷积)。函数
gaussian_laplace使用gaussian_filter来计算拉普拉斯滤波器,以计算二阶导数。高斯滤波器沿每个轴的标准差通过参数 sigma 作为序列或数字传递。如果 sigma 不是序列而是一个单一数字,则滤波器的标准差沿所有方向都相等。
梯度幅度定义为所有方向上的梯度平方和的平方根。与通用拉普拉斯函数类似,有一个 generic_gradient_magnitude 函数可以计算数组的梯度幅度。
函数
generic_gradient_magnitude使用通过derivative传递的函数来计算梯度幅度,以计算一阶导数。函数derivative应具有以下签名derivative(input, axis, output, mode, cval, *extra_arguments, **extra_keywords)
它应该沿着维度 *axis* 计算导数。如果 *output* 不是
None,它应该使用它作为输出并返回None,否则它应该返回结果。*mode*、*cval* 具有通常的含义。*extra_arguments* 和 *extra_keywords* 参数可用于传递一个额外的参数元组和一个命名参数字典,这些参数和字典在每次调用 *derivative* 时传递。
例如,
sobel函数符合所需签名>>> a = np.zeros((5, 5)) >>> a[2, 2] = 1 >>> from scipy.ndimage import sobel, generic_gradient_magnitude >>> generic_gradient_magnitude(a, sobel) array([[ 0. , 0. , 0. , 0. , 0. ], [ 0. , 1.41421356, 2. , 1.41421356, 0. ], [ 0. , 2. , 0. , 2. , 0. ], [ 0. , 1.41421356, 2. , 1.41421356, 0. ], [ 0. , 0. , 0. , 0. , 0. ]])
有关使用 *extra_arguments* 和 *extra_keywords* 参数的示例,请参阅
generic_laplace的文档。
sobel 和 prewitt 函数符合所需签名,因此可以直接与 generic_gradient_magnitude 一起使用。
函数
gaussian_gradient_magnitude使用gaussian_filter计算梯度幅度以计算一阶导数。高斯滤波器沿每个轴的标准差通过参数 *sigma* 作为序列或数字传递。如果 *sigma* 不是序列而是一个数字,则滤波器的标准差沿所有方向都相等。
通用滤波器函数#
为了实现滤波器函数,可以使用接受可调用对象的通用函数,该对象实现滤波操作。对输入和输出数组的迭代由这些通用函数处理,以及边界条件的实现等细节。只需要提供一个实现回调函数的可调用对象,该回调函数执行实际的滤波工作。回调函数也可以用 C 编写,并使用 PyCapsule 传递(有关更多信息,请参阅 用 C 扩展 scipy.ndimage)。
generic_filter1d函数实现了一个通用的 1-D 滤波函数,其中实际的滤波操作必须作为 Python 函数(或其他可调用对象)提供。generic_filter1d函数遍历数组的各行,并在每行调用function。 传递给function的参数是numpy.float64类型的 1-D 数组。 第一个数组包含当前行的值。 它根据 filter_size 和 origin 参数在开头和结尾进行扩展。 第二个数组应该在内存中进行修改,以提供该行的输出值。 例如,考虑沿一个维度的相关性>>> a = np.arange(12).reshape(3,4) >>> correlate1d(a, [1, 2, 3]) array([[ 3, 8, 14, 17], [27, 32, 38, 41], [51, 56, 62, 65]])
可以使用
generic_filter1d实现相同的操作,如下所示>>> def fnc(iline, oline): ... oline[...] = iline[:-2] + 2 * iline[1:-1] + 3 * iline[2:] ... >>> from scipy.ndimage import generic_filter1d >>> generic_filter1d(a, fnc, 3) array([[ 3, 8, 14, 17], [27, 32, 38, 41], [51, 56, 62, 65]])
这里,内核的原点(默认情况下)被假定为位于长度为 3 的滤波器的中间。 因此,在调用函数之前,每条输入行都在开头和结尾扩展了一个值。
可以选择定义额外的参数并将其传递给滤波函数。 extra_arguments 和 extra_keywords 参数可用于传递额外的参数元组和/或命名参数字典,这些参数和/或字典在每次调用时传递给导数。 例如,我们可以将滤波器的参数作为参数传递
>>> def fnc(iline, oline, a, b): ... oline[...] = iline[:-2] + a * iline[1:-1] + b * iline[2:] ... >>> generic_filter1d(a, fnc, 3, extra_arguments = (2, 3)) array([[ 3, 8, 14, 17], [27, 32, 38, 41], [51, 56, 62, 65]])
或者
>>> generic_filter1d(a, fnc, 3, extra_keywords = {'a':2, 'b':3}) array([[ 3, 8, 14, 17], [27, 32, 38, 41], [51, 56, 62, 65]])
generic_filter函数实现了一个通用的滤波函数,其中实际的滤波操作必须作为 Python 函数(或其他可调用对象)提供。generic_filter函数遍历数组,并在每个元素处调用function。function的参数是numpy.float64类型的 1-D 数组,其中包含当前元素周围在滤波器足迹内的值。 该函数应返回一个可以转换为双精度数的单个值。 例如,考虑一个相关性>>> a = np.arange(12).reshape(3,4) >>> correlate(a, [[1, 0], [0, 3]]) array([[ 0, 3, 7, 11], [12, 15, 19, 23], [28, 31, 35, 39]])
可以使用 generic_filter 实现相同的操作,如下所示
>>> def fnc(buffer): ... return (buffer * np.array([1, 3])).sum() ... >>> from scipy.ndimage import generic_filter >>> generic_filter(a, fnc, footprint = [[1, 0], [0, 1]]) array([[ 0, 3, 7, 11], [12, 15, 19, 23], [28, 31, 35, 39]])
这里,指定了一个仅包含两个元素的内核占用空间。因此,滤波函数接收长度为 2 的缓冲区,该缓冲区与适当的权重相乘,并将结果求和。
调用
generic_filter时,必须提供矩形内核的大小或内核的占用空间。如果提供了 size 参数,则它必须是大小序列或单个数字,在这种情况下,假定滤波器的大小沿每个轴都相等。如果提供了 footprint,则它必须是一个数组,通过其非零元素定义内核的形状。可以选择定义额外的参数并将其传递给滤波函数。 extra_arguments 和 extra_keywords 参数可用于传递额外的参数元组和/或命名参数字典,这些参数和/或字典在每次调用时传递给导数。 例如,我们可以将滤波器的参数作为参数传递
>>> def fnc(buffer, weights): ... weights = np.asarray(weights) ... return (buffer * weights).sum() ... >>> generic_filter(a, fnc, footprint = [[1, 0], [0, 1]], extra_arguments = ([1, 3],)) array([[ 0, 3, 7, 11], [12, 15, 19, 23], [28, 31, 35, 39]])
或者
>>> generic_filter(a, fnc, footprint = [[1, 0], [0, 1]], extra_keywords= {'weights': [1, 3]}) array([[ 0, 3, 7, 11], [12, 15, 19, 23], [28, 31, 35, 39]])
这些函数从最后一个轴开始遍历行或元素,即最后一个索引变化最快。对于需要根据空间位置调整滤波器的案例,保证了这种迭代顺序。以下是如何使用实现滤波器并跟踪当前坐标的类的示例。它执行与上面针对 generic_filter 描述的相同滤波操作,但另外打印当前坐标
>>> a = np.arange(12).reshape(3,4)
>>>
>>> class fnc_class:
... def __init__(self, shape):
... # store the shape:
... self.shape = shape
... # initialize the coordinates:
... self.coordinates = [0] * len(shape)
...
... def filter(self, buffer):
... result = (buffer * np.array([1, 3])).sum()
... print(self.coordinates)
... # calculate the next coordinates:
... axes = list(range(len(self.shape)))
... axes.reverse()
... for jj in axes:
... if self.coordinates[jj] < self.shape[jj] - 1:
... self.coordinates[jj] += 1
... break
... else:
... self.coordinates[jj] = 0
... return result
...
>>> fnc = fnc_class(shape = (3,4))
>>> generic_filter(a, fnc.filter, footprint = [[1, 0], [0, 1]])
[0, 0]
[0, 1]
[0, 2]
[0, 3]
[1, 0]
[1, 1]
[1, 2]
[1, 3]
[2, 0]
[2, 1]
[2, 2]
[2, 3]
array([[ 0, 3, 7, 11],
[12, 15, 19, 23],
[28, 31, 35, 39]])
对于 generic_filter1d 函数,相同的方法也适用,只是该函数不遍历正在滤波的轴。针对 generic_filter1d 的示例如下
>>> a = np.arange(12).reshape(3,4)
>>>
>>> class fnc1d_class:
... def __init__(self, shape, axis = -1):
... # store the filter axis:
... self.axis = axis
... # store the shape:
... self.shape = shape
... # initialize the coordinates:
... self.coordinates = [0] * len(shape)
...
... def filter(self, iline, oline):
... oline[...] = iline[:-2] + 2 * iline[1:-1] + 3 * iline[2:]
... print(self.coordinates)
... # calculate the next coordinates:
... axes = list(range(len(self.shape)))
... # skip the filter axis:
... del axes[self.axis]
... axes.reverse()
... for jj in axes:
... if self.coordinates[jj] < self.shape[jj] - 1:
... self.coordinates[jj] += 1
... break
... else:
... self.coordinates[jj] = 0
...
>>> fnc = fnc1d_class(shape = (3,4))
>>> generic_filter1d(a, fnc.filter, 3)
[0, 0]
[1, 0]
[2, 0]
array([[ 3, 8, 14, 17],
[27, 32, 38, 41],
[51, 56, 62, 65]])
频域滤波器#
本节描述的函数在傅里叶域执行滤波操作。因此,此类函数的输入数组应与逆傅里叶变换函数兼容,例如来自 numpy.fft 模块的函数。因此,我们必须处理可能为实数或复数傅里叶变换结果的数组。在实数傅里叶变换的情况下,仅存储对称复数变换的一半。此外,需要知道对实数 fft 进行变换的轴的长度。此处描述的函数提供了一个参数 n,在实数变换的情况下,该参数必须等于变换前实数变换轴的长度。如果此参数小于零,则假定输入数组是复数傅里叶变换的结果。参数 axis 可用于指示沿哪个轴执行实数变换。
fourier_shift函数将输入数组乘以给定位移的位移操作的多维傅里叶变换。shift 参数是每个维度的位移序列或所有维度的单个值。fourier_gaussian函数将输入数组乘以具有给定标准差 sigma 的高斯滤波器的多维傅里叶变换。sigma 参数是每个维度的值序列或所有维度的单个值。fourier_uniform函数将输入数组乘以具有给定大小 size 的均匀滤波器的多维傅里叶变换。size 参数是每个维度的值序列或所有维度的单个值。fourier_ellipsoid函数将输入数组乘以具有给定大小 size 的椭圆形滤波器的多维傅里叶变换。size 参数是每个维度的值序列或所有维度的单个值。此函数仅针对维度 1、2 和 3 实现。
插值函数#
本节介绍了基于 B 样条理论的各种插值函数。关于 B 样条的良好介绍可以在 [1] 中找到,其中给出了图像插值的详细算法,见 [5]。
样条预滤波器#
使用大于 1 阶的样条进行插值需要一个预滤波步骤。在 插值函数 部分描述的插值函数通过调用 spline_filter 来执行预滤波,但可以通过将 prefilter 关键字设置为 False 来指示它们不要执行此操作。如果对同一个数组执行多个插值操作,这将很有用。在这种情况下,只进行一次预滤波并将预滤波后的数组用作插值函数的输入更有效。以下两个函数实现了预滤波
spline_filter1d函数沿给定轴计算一维样条滤波器。可以选择提供输出数组。样条的阶数必须大于 1 且小于 6。spline_filter函数计算多维样条滤波器。注意
多维滤波器实现为一系列一维样条滤波器。中间数组存储在与输出相同的类型中。因此,如果请求具有有限精度的输出,则结果可能不精确,因为中间结果可能以不足的精度存储。可以通过指定高精度的输出类型来防止这种情况。
插值边界处理#
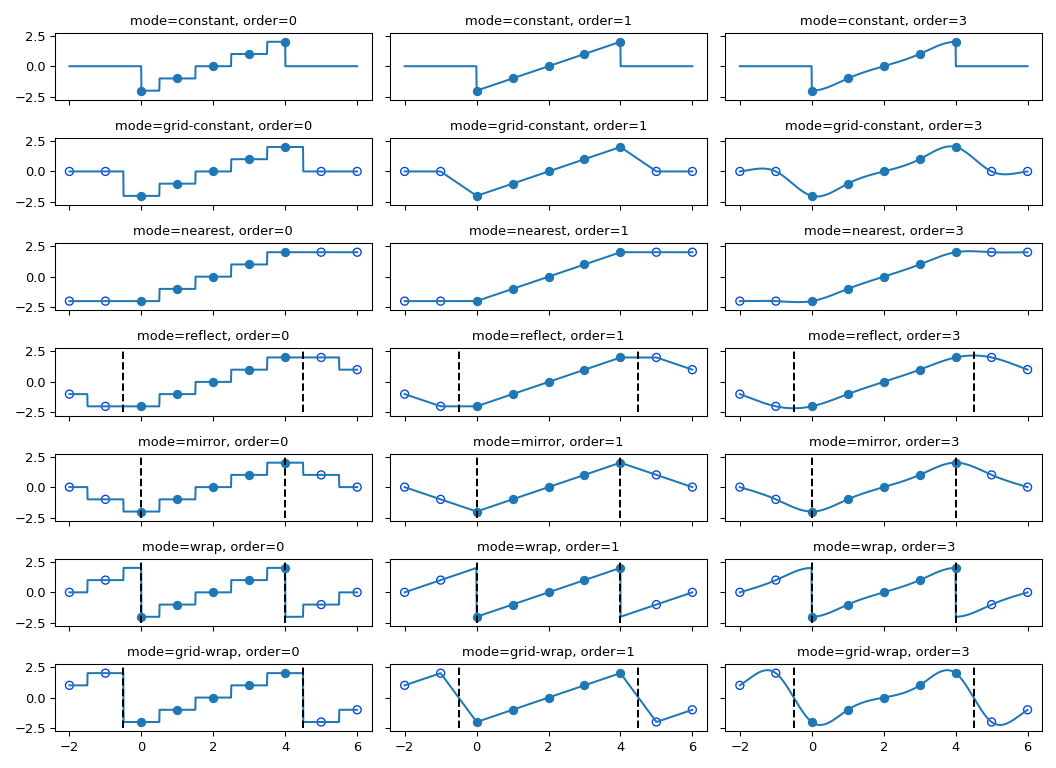
所有插值函数都采用样条插值来实现对输入数组的某种几何变换。这需要将输出坐标映射到输入坐标,因此,可能会出现需要边界之外的输入值的情况。这个问题的解决方法与滤波函数中描述的多维滤波函数相同。因此,这些函数都支持一个mode参数,用于确定如何处理边界,以及一个cval参数,用于在使用“常数”模式时提供一个常数值。所有模式的行为,包括在非整数位置的行为,如下所示。请注意,边界处理方式并非所有模式都相同;reflect(也称为grid-mirror)和grid-wrap涉及围绕图像样本之间中点(虚线)的对称或重复,而模式mirror和wrap将图像视为其范围恰好以第一个和最后一个样本点结束,而不是以最后一个样本点结束0.5个样本。
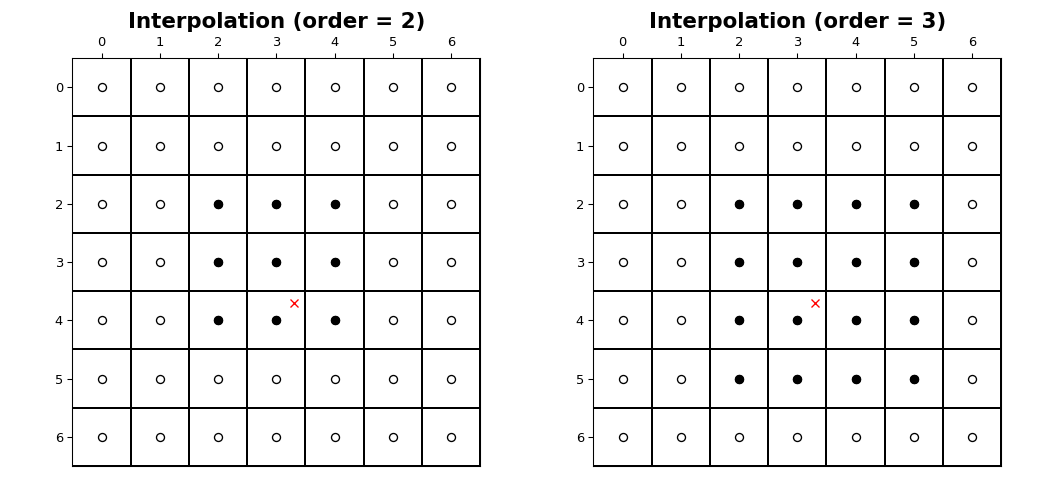
图像样本的坐标落在从 0 到shape[i] - 1范围内的整数采样位置上,沿着每个轴,i。下图说明了在形状为(7, 7)的图像中,位置为(3.7, 3.3)的点的插值。对于阶数为n的插值,n + 1个样本参与每个轴的插值。实心圆表示参与红色 x 位置处的值插值的采样位置。
插值函数#
geometric_transform函数对输入应用任意几何变换。给定的mapping函数在输出中的每个点处被调用,以找到输入中的对应坐标。mapping必须是一个可调用对象,它接受一个长度等于输出数组秩的元组,并返回一个长度等于输入数组秩的元组,作为对应的输入坐标。输出形状和输出类型可以选择提供。如果没有给出,它们将等于输入形状和类型。例如
>>> a = np.arange(12).reshape(4,3).astype(np.float64) >>> def shift_func(output_coordinates): ... return (output_coordinates[0] - 0.5, output_coordinates[1] - 0.5) ... >>> from scipy.ndimage import geometric_transform >>> geometric_transform(a, shift_func) array([[ 0. , 0. , 0. ], [ 0. , 1.3625, 2.7375], [ 0. , 4.8125, 6.1875], [ 0. , 8.2625, 9.6375]])
可以选择定义额外的参数并将其传递给滤波函数。extra_arguments和extra_keywords参数可以用来传递一个额外的参数元组和/或一个命名参数字典,这些参数和/或字典在每次调用时传递给derivative。例如,我们可以将我们示例中的偏移量作为参数传递
>>> def shift_func(output_coordinates, s0, s1): ... return (output_coordinates[0] - s0, output_coordinates[1] - s1) ... >>> geometric_transform(a, shift_func, extra_arguments = (0.5, 0.5)) array([[ 0. , 0. , 0. ], [ 0. , 1.3625, 2.7375], [ 0. , 4.8125, 6.1875], [ 0. , 8.2625, 9.6375]])
或者
>>> geometric_transform(a, shift_func, extra_keywords = {'s0': 0.5, 's1': 0.5}) array([[ 0. , 0. , 0. ], [ 0. , 1.3625, 2.7375], [ 0. , 4.8125, 6.1875], [ 0. , 8.2625, 9.6375]])
注意
映射函数也可以用 C 语言编写,并使用
scipy.LowLevelCallable传递。有关更多信息,请参见 在 C 中扩展 scipy.ndimage。函数
map_coordinates使用给定的坐标数组应用任意坐标变换。输出的形状通过删除第一个轴从坐标数组的形状派生。参数 coordinates 用于为输出中的每个点找到输入中相应的坐标。coordinates 沿第一个轴的值是在输入数组中找到输出值的坐标。(另请参见 numarray 的 coordinates 函数。)由于坐标可能是非整数坐标,因此通过请求的阶数的样条插值确定这些坐标处输入的值。以下示例在
(0.5, 0.5)和(1, 2)处对二维数组进行插值>>> a = np.arange(12).reshape(4,3).astype(np.float64) >>> a array([[ 0., 1., 2.], [ 3., 4., 5.], [ 6., 7., 8.], [ 9., 10., 11.]]) >>> from scipy.ndimage import map_coordinates >>> map_coordinates(a, [[0.5, 2], [0.5, 1]]) array([ 1.3625, 7.])
函数
affine_transform对输入数组应用仿射变换。给定的变换 matrix 和 offset 用于为输出中的每个点找到输入中相应的坐标。通过请求的阶数的样条插值确定计算出的坐标处输入的值。变换 matrix 必须是二维的,也可以作为一维序列或数组给出。在后一种情况下,假设矩阵是对角线。然后应用更有效的插值算法,该算法利用问题的可分离性。可以可选地提供输出形状和输出类型。如果未给出,它们将等于输入形状和类型。函数
shift使用请求的 order 的样条插值返回输入的移位版本。函数
zoom使用请求的 order 的样条插值返回输入的缩放版本。函数
rotate返回输入数组,该数组在由参数 axes 给定的两个轴定义的平面上旋转,使用所请求的 order 的样条插值。角度必须以度为单位给出。如果 reshape 为真,则输出数组的大小将调整为包含旋转后的输入。
形态学#
二值形态学#
函数
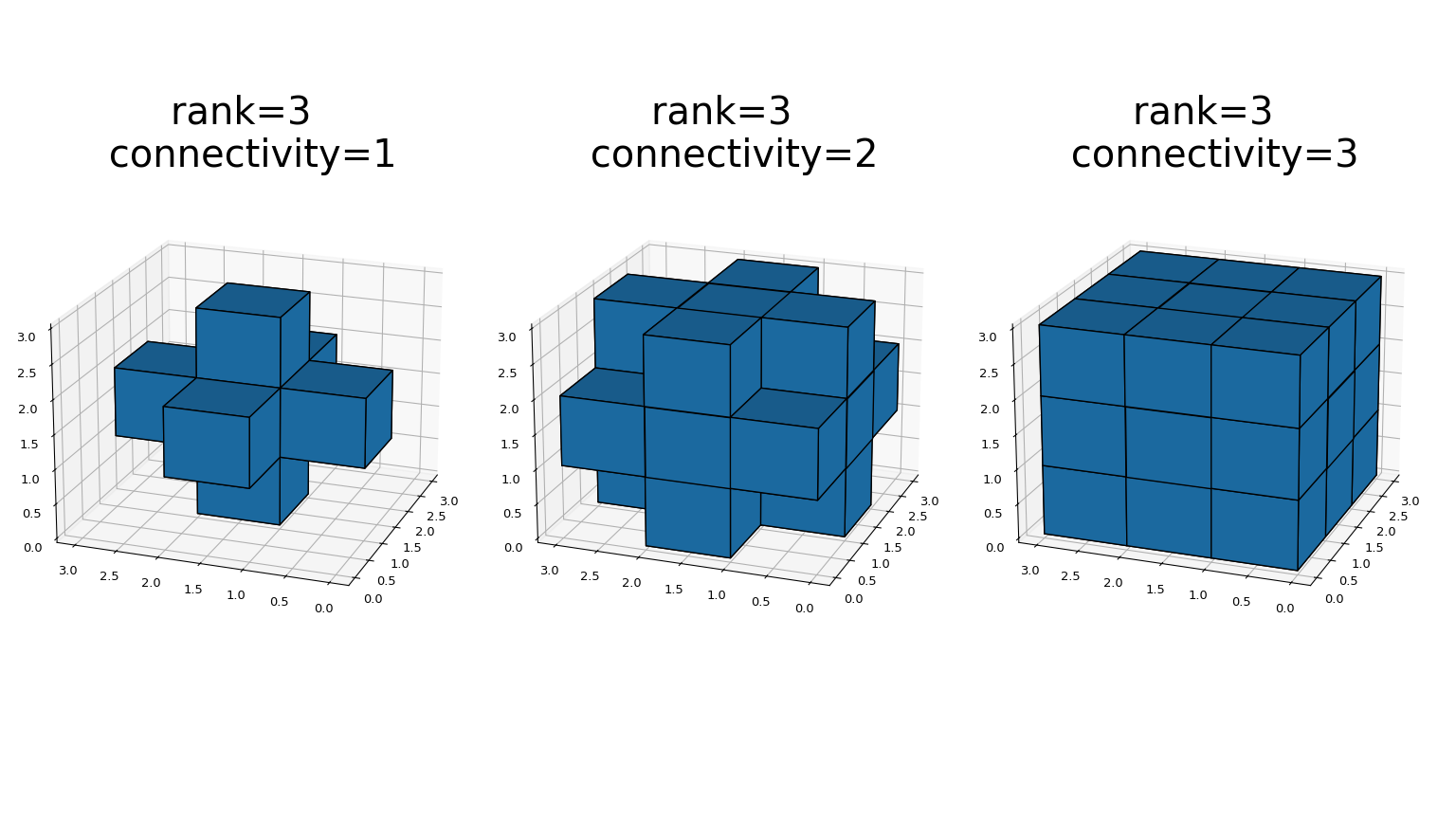
generate_binary_structure生成用于二值形态学运算的二值结构元素。必须提供结构的 rank。返回的结构的大小在每个方向上都等于 3。如果元素到中心的欧几里得距离的平方小于或等于 connectivity,则每个元素的值都等于 1。例如,2-D 4 连接和 8 连接结构如下生成>>> from scipy.ndimage import generate_binary_structure >>> generate_binary_structure(2, 1) array([[False, True, False], [ True, True, True], [False, True, False]], dtype=bool) >>> generate_binary_structure(2, 2) array([[ True, True, True], [ True, True, True], [ True, True, True]], dtype=bool)
这是 generate_binary_structure 在 3D 中的视觉演示
大多数二值形态学函数可以用基本运算腐蚀和膨胀来表示,如下所示
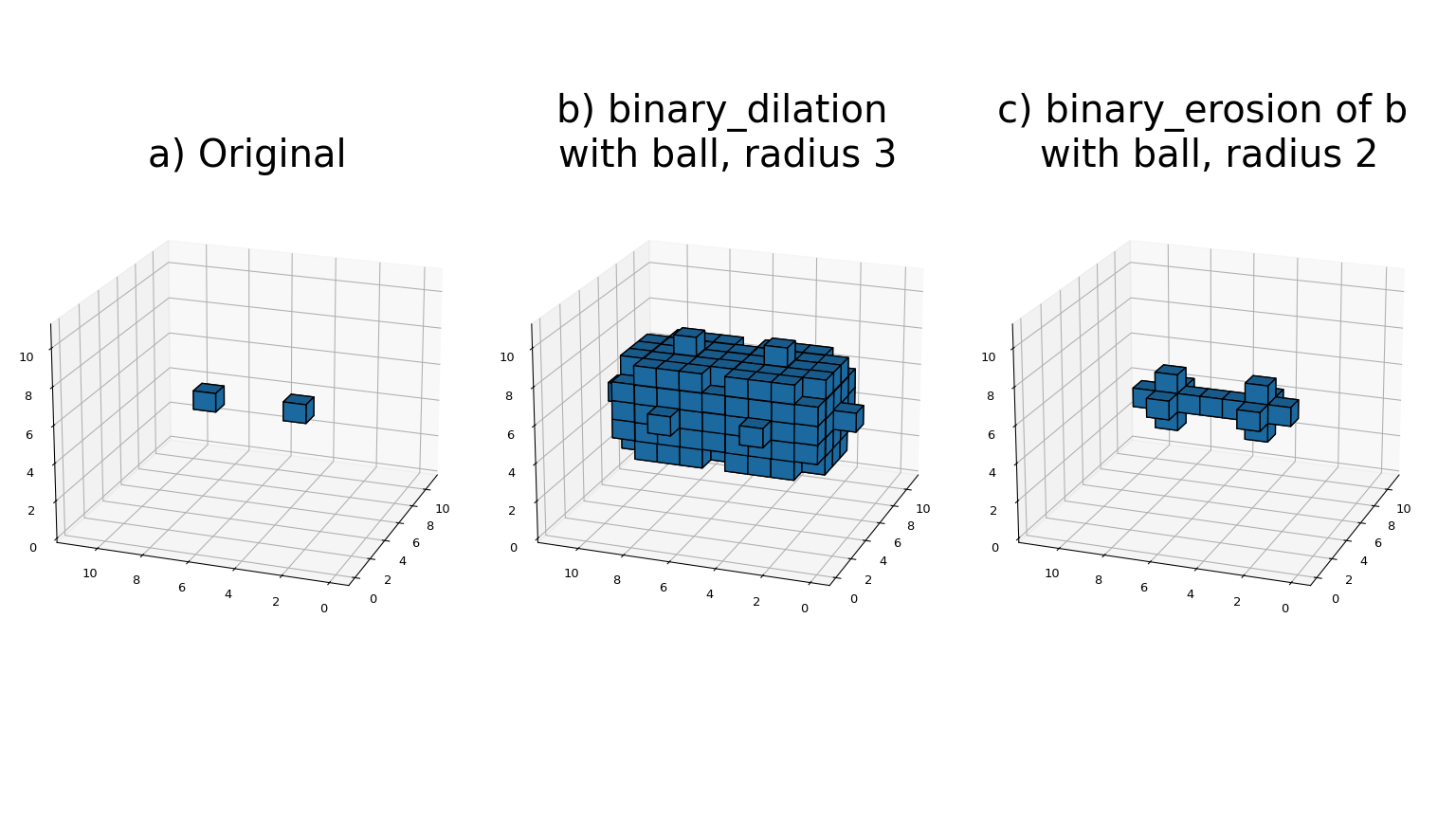
函数
binary_erosion使用给定的结构元素实现任意秩数组的二值腐蚀。origin 参数控制结构元素的放置,如 Filter functions 中所述。如果未提供结构元素,则使用generate_binary_structure生成连接性等于 1 的元素。border_value 参数给出边界外数组的值。腐蚀重复 iterations 次。如果 iterations 小于 1,则腐蚀重复执行,直到结果不再改变。如果给出了 mask 数组,则在每次迭代中,只有那些在相应的掩码元素处具有真值的元素才会被修改。binary_dilation函数使用给定的结构元素实现任意秩数组的二值膨胀。origin 参数控制结构元素的放置,如 Filter functions 中所述。如果没有提供结构元素,则使用generate_binary_structure生成连接性等于 1 的元素。border_value 参数给出数组边界之外的值。膨胀重复 iterations 次。如果 iterations 小于 1,则重复膨胀,直到结果不再改变。如果给出 mask 数组,则在每次迭代中只修改对应掩码元素为真值的元素。
以下是如何使用 binary_dilation 查找所有接触边界的元素的示例,方法是使用数据数组作为掩码,从边界重复膨胀空数组
>>> struct = np.array([[0, 1, 0], [1, 1, 1], [0, 1, 0]])
>>> a = np.array([[1,0,0,0,0], [1,1,0,1,0], [0,0,1,1,0], [0,0,0,0,0]])
>>> a
array([[1, 0, 0, 0, 0],
[1, 1, 0, 1, 0],
[0, 0, 1, 1, 0],
[0, 0, 0, 0, 0]])
>>> from scipy.ndimage import binary_dilation
>>> binary_dilation(np.zeros(a.shape), struct, -1, a, border_value=1)
array([[ True, False, False, False, False],
[ True, True, False, False, False],
[False, False, False, False, False],
[False, False, False, False, False]], dtype=bool)
binary_erosion 和 binary_dilation 函数都具有一个 *iterations* 参数,它允许腐蚀或膨胀重复多次。用给定结构重复腐蚀或膨胀 *n* 次等效于用一个结构进行腐蚀或膨胀,该结构本身被膨胀了 *n-1* 次。提供了一个函数,允许计算一个结构,该结构本身被膨胀了多次。
iterate_structure函数通过将输入结构 *iteration* - 1 次膨胀自身来返回一个结构。例如
>>> struct = generate_binary_structure(2, 1) >>> struct array([[False, True, False], [ True, True, True], [False, True, False]], dtype=bool) >>> from scipy.ndimage import iterate_structure >>> iterate_structure(struct, 2) array([[False, False, True, False, False], [False, True, True, True, False], [ True, True, True, True, True], [False, True, True, True, False], [False, False, True, False, False]], dtype=bool) If the origin of the original structure is equal to 0, then it is also equal to 0 for the iterated structure. If not, the origin must also be adapted if the equivalent of the *iterations* erosions or dilations must be achieved with the iterated structure. The adapted origin is simply obtained by multiplying with the number of iterations. For convenience, the :func:`iterate_structure` also returns the adapted origin if the *origin* parameter is not ``None``: .. code:: python >>> iterate_structure(struct, 2, -1) (array([[False, False, True, False, False], [False, True, True, True, False], [ True, True, True, True, True], [False, True, True, True, False], [False, False, True, False, False]], dtype=bool), [-2, -2])
其他形态学操作可以用腐蚀和膨胀来定义。以下函数为方便起见提供了其中一些操作。
binary_opening函数使用给定的结构元素实现任意秩数组的二值开运算。二值开运算等效于使用相同结构元素进行二值腐蚀,然后进行二值膨胀。origin 参数控制结构元素的放置,如 Filter functions 中所述。如果没有提供结构元素,则使用generate_binary_structure生成一个连接性等于 1 的元素。*iterations* 参数给出执行的腐蚀次数,然后进行相同次数的膨胀。binary_closing函数使用给定的结构元素实现任意秩数组的二值闭运算。二值闭运算等效于使用相同结构元素进行二值膨胀,然后进行二值腐蚀。origin 参数控制结构元素的放置,如 Filter functions 中所述。如果没有提供结构元素,则使用generate_binary_structure生成一个连接性等于 1 的元素。*iterations* 参数给出执行的膨胀次数,然后进行相同次数的腐蚀。在二值图像中,
binary_fill_holes函数用于闭合物体中的孔洞,其中结构定义了孔洞的连通性。origin 参数控制结构元素的放置位置,如 Filter functions 中所述。如果没有提供结构元素,则使用generate_binary_structure生成一个连通性等于 1 的元素。binary_hit_or_miss函数实现了具有给定结构元素的任意秩数组的二值命中或错过变换。命中或错过变换通过使用第一个结构对输入进行腐蚀、使用第二个结构对输入的逻辑非进行腐蚀,然后对这两个腐蚀进行逻辑与运算来计算。origin 参数控制结构元素的放置位置,如 Filter functions 中所述。如果 origin2 等于None,则将其设置为等于 origin1 参数。如果没有提供第一个结构元素,则使用generate_binary_structure生成一个连通性等于 1 的结构元素。如果 structure2 未提供,则将其设置为 structure1 的逻辑非。
灰度形态学#
灰度形态学操作是二值形态学操作的等效操作,它们作用于具有任意值的数组。下面,我们将描述腐蚀、膨胀、开运算和闭运算的灰度等效操作。这些操作的实现方式与滤波函数中描述的滤波器类似,我们参考本节来描述滤波器核和足迹,以及数组边界的处理方式。灰度形态学操作可以选择性地接受一个结构参数,该参数给出结构元素的值。如果未给出此参数,则结构元素被假定为扁平的,其值为零。结构的形状可以选择性地由足迹参数定义。如果未给出此参数,则结构被假定为矩形的,其大小等于结构数组的维度,或者由大小参数定义,如果未给出结构。大小参数仅在结构和足迹均未给出时使用,在这种情况下,结构元素被假定为矩形且扁平,其维度由大小给出。如果提供大小参数,则它必须是一个尺寸序列或单个数字,在这种情况下,滤波器的大小被假定为沿每个轴相等。如果提供足迹参数,则它必须是一个数组,通过其非零元素定义核的形状。
与二值腐蚀和膨胀类似,存在灰度腐蚀和膨胀操作
grey_erosion函数计算多维灰度腐蚀。grey_dilation函数计算多维灰度膨胀。
灰度开运算和闭运算可以类似于它们的二值对应物来定义
grey_opening函数实现任意秩数组的灰度开运算。灰度开运算等效于灰度腐蚀后跟灰度膨胀。grey_closing函数实现任意秩数组的灰度闭运算。灰度开运算等效于灰度膨胀后跟灰度腐蚀。函数
morphological_gradient实现任意秩数组的灰度形态梯度。灰度形态梯度等于灰度膨胀和灰度腐蚀的差值。函数
morphological_laplace实现任意秩数组的灰度形态拉普拉斯算子。灰度形态拉普拉斯算子等于灰度膨胀和灰度腐蚀的和减去两倍的输入。函数
white_tophat实现任意秩数组的白顶帽滤波器。白顶帽等于输入和灰度开运算的差值。函数
black_tophat实现任意秩数组的黑顶帽滤波器。黑顶帽等于灰度闭运算和输入的差值。
距离变换#
距离变换用于计算对象中每个元素到背景的最小距离。以下函数实现了三种不同距离度量的距离变换:欧几里得距离、城市街区距离和棋盘距离。
函数
distance_transform_cdt使用一种 chamfer 类型的算法来计算输入的距离变换,通过将每个对象元素(由大于零的值定义)替换为到背景(所有非对象元素)的最短距离。结构决定了所执行的 chamfering 类型。如果结构等于 'cityblock',则使用generate_binary_structure生成一个结构,其平方距离等于 1。如果结构等于 'chessboard',则使用generate_binary_structure生成一个结构,其平方距离等于数组的秩。这些选择对应于二维中城市街区距离和棋盘距离的常见解释。除了距离变换之外,还可以计算特征变换。在这种情况下,最接近的背景元素的索引将沿结果的第一轴返回。return_distances 和 return_indices 标志可用于指示是否必须返回距离变换、特征变换或两者。
distances 和 indices 参数可用于提供可选的输出数组,这些数组必须具有正确的尺寸和类型(均为
numpy.int32)。用于实现此函数的算法的基础在 [2] 中进行了描述。函数
distance_transform_edt通过将每个对象元素(由大于零的值定义)替换为到背景(所有非对象元素)的最短欧几里得距离,来计算输入的精确欧几里得距离变换。除了距离变换之外,还可以计算特征变换。在这种情况下,最接近的背景元素的索引将沿结果的第一轴返回。return_distances 和 return_indices 标志可用于指示是否必须返回距离变换、特征变换或两者。
可以选择通过 sampling 参数给出沿每个轴的采样,该参数应为长度等于输入秩的序列,或者为单个数字,其中假设沿所有轴的采样相等。
distances 和 indices 参数可用于提供可选的输出数组,这些数组必须具有正确的尺寸和类型(
numpy.float64和numpy.int32)。用于实现此函数的算法在 [3] 中进行了描述。函数
distance_transform_bf使用蛮力算法来计算输入的距离变换,通过将每个对象元素(由大于零的值定义)替换为到背景(所有非对象元素)的最短距离。度量必须是“euclidean”、“cityblock”或“chessboard”之一。除了距离变换之外,还可以计算特征变换。在这种情况下,最接近的背景元素的索引将沿结果的第一轴返回。return_distances 和 return_indices 标志可用于指示是否必须返回距离变换、特征变换或两者。
可选地,可以通过sampling参数指定每个轴的采样,该参数应为与输入秩长度相同的序列,或者为单个数字,在这种情况下,假设所有轴的采样相同。此参数仅在使用欧几里得距离变换时使用。
distances和indices参数可用于提供可选的输出数组,这些数组必须具有正确的尺寸和类型(
numpy.float64和numpy.int32)。注意
此函数使用缓慢的暴力算法,函数
distance_transform_cdt可用于更有效地计算城市街区和棋盘距离变换。函数distance_transform_edt可用于更有效地计算精确的欧几里得距离变换。
分割和标记#
分割是指将感兴趣的目标从背景中分离出来的过程。最简单的方法可能是强度阈值化,这可以通过numpy函数轻松完成
>>> a = np.array([[1,2,2,1,1,0],
... [0,2,3,1,2,0],
... [1,1,1,3,3,2],
... [1,1,1,1,2,1]])
>>> np.where(a > 1, 1, 0)
array([[0, 1, 1, 0, 0, 0],
[0, 1, 1, 0, 1, 0],
[0, 0, 0, 1, 1, 1],
[0, 0, 0, 0, 1, 0]])
结果是二值图像,其中各个目标仍然需要被识别和标记。函数label生成一个数组,其中每个目标都被分配一个唯一的数字
函数
label生成一个数组,其中输入中的目标用整数索引标记。它返回一个包含目标标签数组和找到的目标数量的元组,除非给出output参数,在这种情况下,只返回目标数量。目标的连通性由结构元素定义。例如,在二维中使用 4 连通结构元素会得到>>> a = np.array([[0,1,1,0,0,0],[0,1,1,0,1,0],[0,0,0,1,1,1],[0,0,0,0,1,0]]) >>> s = [[0, 1, 0], [1,1,1], [0,1,0]] >>> from scipy.ndimage import label >>> label(a, s) (array([[0, 1, 1, 0, 0, 0], [0, 1, 1, 0, 2, 0], [0, 0, 0, 2, 2, 2], [0, 0, 0, 0, 2, 0]]), 2)
这两个目标没有连接,因为我们无法放置结构元素,使其与这两个目标重叠。但是,8 连通结构元素会导致只有一个目标
>>> a = np.array([[0,1,1,0,0,0],[0,1,1,0,1,0],[0,0,0,1,1,1],[0,0,0,0,1,0]]) >>> s = [[1,1,1], [1,1,1], [1,1,1]] >>> label(a, s)[0] array([[0, 1, 1, 0, 0, 0], [0, 1, 1, 0, 1, 0], [0, 0, 0, 1, 1, 1], [0, 0, 0, 0, 1, 0]])
如果未提供结构元素,则通过调用
generate_binary_structure(参见 二值形态学)生成一个结构元素,使用连接性为 1(在二维中是第一个示例的 4 连接结构)。输入可以是任何类型,任何不等于零的值都被视为对象的一部分。如果您需要“重新标记”对象索引数组,例如在删除不需要的对象之后,这很有用。只需再次将标签函数应用于索引数组即可。例如>>> l, n = label([1, 0, 1, 0, 1]) >>> l array([1, 0, 2, 0, 3]) >>> l = np.where(l != 2, l, 0) >>> l array([1, 0, 0, 0, 3]) >>> label(l)[0] array([1, 0, 0, 0, 2])
注意
label使用的结构元素被假定为对称的。
还有许多其他用于分割的方法,例如,从可以通过导数滤波器获得的对象边界的估计。一种这样的方法是分水岭分割。函数 watershed_ift 生成一个数组,其中每个对象都分配了一个唯一的标签,来自一个定位对象边界的数组,例如,由梯度幅度滤波器生成。它使用一个包含对象初始标记的数组
watershed_ift函数应用了从标记算法进行的分水岭,使用图像森林变换,如 [4] 中所述。此函数的输入是应用变换的数组,以及一个标记数组,该数组通过唯一的标签指定对象,其中任何非零值都是标记。例如
>>> input = np.array([[0, 0, 0, 0, 0, 0, 0], ... [0, 1, 1, 1, 1, 1, 0], ... [0, 1, 0, 0, 0, 1, 0], ... [0, 1, 0, 0, 0, 1, 0], ... [0, 1, 0, 0, 0, 1, 0], ... [0, 1, 1, 1, 1, 1, 0], ... [0, 0, 0, 0, 0, 0, 0]], np.uint8) >>> markers = np.array([[1, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 2, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0]], np.int8) >>> from scipy.ndimage import watershed_ift >>> watershed_ift(input, markers) array([[1, 1, 1, 1, 1, 1, 1], [1, 1, 2, 2, 2, 1, 1], [1, 2, 2, 2, 2, 2, 1], [1, 2, 2, 2, 2, 2, 1], [1, 2, 2, 2, 2, 2, 1], [1, 1, 2, 2, 2, 1, 1], [1, 1, 1, 1, 1, 1, 1]], dtype=int8)
这里,使用了两个标记来指定一个对象(marker = 2)和背景(marker = 1)。处理这些标记的顺序是任意的:将背景标记移动到数组的右下角会产生不同的结果
>>> markers = np.array([[0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 2, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 1]], np.int8) >>> watershed_ift(input, markers) array([[1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1], [1, 1, 2, 2, 2, 1, 1], [1, 1, 2, 2, 2, 1, 1], [1, 1, 2, 2, 2, 1, 1], [1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1]], dtype=int8)
结果是对象(marker = 2)更小,因为第二个标记更早被处理。如果第一个标记应该指定一个背景对象,这可能不是期望的效果。因此,
watershed_ift将负值的标记显式地视为背景标记,并在处理完普通标记后处理它们。例如,用负标记替换第一个标记会得到与第一个示例类似的结果>>> markers = np.array([[0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 2, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, 0], ... [0, 0, 0, 0, 0, 0, -1]], np.int8) >>> watershed_ift(input, markers) array([[-1, -1, -1, -1, -1, -1, -1], [-1, -1, 2, 2, 2, -1, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, -1, 2, 2, 2, -1, -1], [-1, -1, -1, -1, -1, -1, -1]], dtype=int8)
对象的连通性由结构元素定义。如果没有提供结构元素,则通过调用
generate_binary_structure(参见 二值形态学)使用连通性 1(在 2D 中为 4 连通结构)来生成一个结构元素。例如,使用 8 连通结构和最后一个示例将产生不同的对象。>>> watershed_ift(input, markers, ... structure = [[1,1,1], [1,1,1], [1,1,1]]) array([[-1, -1, -1, -1, -1, -1, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, 2, 2, 2, 2, 2, -1], [-1, -1, -1, -1, -1, -1, -1]], dtype=int8)
注意
watershed_ift的实现将输入数据类型限制为numpy.uint8和numpy.uint16。
对象测量#
给定一个标记对象的数组,可以测量单个对象的属性。 find_objects 函数可用于生成一个切片列表,该列表对于每个对象,都给出完全包含该对象的最小子数组。
find_objects函数查找标记数组中的所有对象,并返回一个切片列表,这些切片对应于包含该对象的数组中的最小区域。例如
>>> a = np.array([[0,1,1,0,0,0],[0,1,1,0,1,0],[0,0,0,1,1,1],[0,0,0,0,1,0]]) >>> l, n = label(a) >>> from scipy.ndimage import find_objects >>> f = find_objects(l) >>> a[f[0]] array([[1, 1], [1, 1]]) >>> a[f[1]] array([[0, 1, 0], [1, 1, 1], [0, 1, 0]])
find_objects函数返回所有对象的切片,除非 max_label 参数大于零,在这种情况下,只返回前 max_label 个对象。如果 label 数组中缺少索引,则返回None而不是切片。例如>>> from scipy.ndimage import find_objects >>> find_objects([1, 0, 3, 4], max_label = 3) [(slice(0, 1, None),), None, (slice(2, 3, None),)]
由 find_objects 生成的切片列表对于查找数组中对象的 position 和尺寸很有用,但也可以用于对单个对象执行测量。假设,我们想要找到图像中一个对象的强度之和
>>> image = np.arange(4 * 6).reshape(4, 6)
>>> mask = np.array([[0,1,1,0,0,0],[0,1,1,0,1,0],[0,0,0,1,1,1],[0,0,0,0,1,0]])
>>> labels = label(mask)[0]
>>> slices = find_objects(labels)
然后我们可以计算第二个对象的元素之和
>>> np.where(labels[slices[1]] == 2, image[slices[1]], 0).sum()
80
但是,这效率不高,对于其他类型的测量也可能更复杂。因此,定义了一些测量函数,这些函数接受对象标签数组和要测量的对象的索引。例如,可以通过以下方式计算强度之和
>>> from scipy.ndimage import sum as ndi_sum
>>> ndi_sum(image, labels, 2)
80
对于大型数组和小对象,在对数组进行切片后调用测量函数效率更高
>>> ndi_sum(image[slices[1]], labels[slices[1]], 2)
80
或者,我们可以通过单个函数调用来测量多个标签的值,并返回一个结果列表。例如,要测量示例中背景和第二个对象的总和,我们可以提供一个标签列表
>>> ndi_sum(image, labels, [0, 2])
array([178.0, 80.0])
下面描述的测量函数都支持index参数,以指示应测量哪些对象。index的默认值为None。这表示所有标签大于零的元素都应被视为单个对象并进行测量。因此,在这种情况下,labels数组被视为由大于零的元素定义的掩码。如果index是一个数字或数字序列,则它给出被测对象的标签。如果index是一个序列,则返回一个结果列表。如果index是一个数字,则返回多个结果的函数将结果作为元组返回,如果index是一个序列,则作为元组列表返回。
该
sum函数使用labels数组作为对象标签,计算具有index给出的标签的对象的元素之和。如果index为None,则所有具有非零标签值的元素都被视为单个对象。如果label为None,则input的所有元素都用于计算。该
mean函数使用labels数组作为对象标签,计算具有index给出的标签的对象的元素的平均值。如果index为None,则所有具有非零标签值的元素都被视为单个对象。如果label为None,则input的所有元素都用于计算。函数
variance计算由index给定的标签所标识的对象的元素方差,使用labels数组作为对象标签。如果index为None,则所有具有非零标签值的元素都被视为单个对象。如果label为None,则input的所有元素都将用于计算。函数
standard_deviation计算由index给定的标签所标识的对象的元素标准差,使用labels数组作为对象标签。如果index为None,则所有具有非零标签值的元素都被视为单个对象。如果label为None,则input的所有元素都将用于计算。函数
minimum计算由index给定的标签所标识的对象的元素最小值,使用labels数组作为对象标签。如果index为None,则所有具有非零标签值的元素都被视为单个对象。如果label为None,则input的所有元素都将用于计算。函数
maximum计算由index给定的标签所标识的对象的元素最大值,使用labels数组作为对象标签。如果index为None,则所有具有非零标签值的元素都被视为单个对象。如果label为None,则input的所有元素都将用于计算。函数
minimum_position计算由 index 指定的标签所对应的对象元素的最小值的位置,使用 labels 数组作为对象标签。如果 index 为None,则所有具有非零标签值的元素都被视为单个对象。如果 label 为None,则计算中使用 input 的所有元素。函数
maximum_position计算由 index 指定的标签所对应的对象元素的最大值的位置,使用 labels 数组作为对象标签。如果 index 为None,则所有具有非零标签值的元素都被视为单个对象。如果 label 为None,则计算中使用 input 的所有元素。函数
extrema计算由 index 指定的标签所对应的对象元素的最小值、最大值及其位置,使用 labels 数组作为对象标签。如果 index 为None,则所有具有非零标签值的元素都被视为单个对象。如果 label 为None,则计算中使用 input 的所有元素。结果是一个元组,包含最小值、最大值、最小值的位置和最大值的位置。结果与由上述函数 minimum、maximum、minimum_position 和 maximum_position 的结果组成的元组相同。函数
center_of_mass计算由 index 指定的标签所对应的对象的质心,使用 labels 数组作为对象标签。如果 index 为None,则所有具有非零标签值的元素都被视为单个对象。如果 label 为None,则计算中使用 input 的所有元素。函数
histogram计算由 index 指定的标签所对应的对象的直方图,使用 labels 数组作为对象标签。如果 index 为None,则所有具有非零标签值的元素都被视为单个对象。如果 label 为None,则计算中使用 input 的所有元素。直方图由其最小值 (min)、最大值 (max) 和 bin 的数量 (bins) 定义。它们以类型为numpy.int32的一维数组形式返回。
在 C 中扩展 scipy.ndimage#
scipy.ndimage 中的几个函数接受回调参数。这可以是 Python 函数,也可以是包含指向 C 函数的指针的 scipy.LowLevelCallable。使用 C 函数通常效率更高,因为它避免了在数组的许多元素上调用 Python 函数的开销。要使用 C 函数,您必须编写一个包含回调函数和返回包含指向回调函数的指针的 scipy.LowLevelCallable 的 C 扩展。
支持回调的函数示例是 geometric_transform,它接受一个回调函数,该函数定义了从所有输出坐标到输入数组中对应坐标的映射。考虑以下 Python 示例,它使用 geometric_transform 来实现一个移位函数。
from scipy import ndimage
def transform(output_coordinates, shift):
input_coordinates = output_coordinates[0] - shift, output_coordinates[1] - shift
return input_coordinates
im = np.arange(12).reshape(4, 3).astype(np.float64)
shift = 0.5
print(ndimage.geometric_transform(im, transform, extra_arguments=(shift,)))
我们也可以用以下 C 代码实现回调函数
/* example.c */
#include <Python.h>
#include <numpy/npy_common.h>
static int
_transform(npy_intp *output_coordinates, double *input_coordinates,
int output_rank, int input_rank, void *user_data)
{
npy_intp i;
double shift = *(double *)user_data;
for (i = 0; i < input_rank; i++) {
input_coordinates[i] = output_coordinates[i] - shift;
}
return 1;
}
static char *transform_signature = "int (npy_intp *, double *, int, int, void *)";
static PyObject *
py_get_transform(PyObject *obj, PyObject *args)
{
if (!PyArg_ParseTuple(args, "")) return NULL;
return PyCapsule_New(_transform, transform_signature, NULL);
}
static PyMethodDef ExampleMethods[] = {
{"get_transform", (PyCFunction)py_get_transform, METH_VARARGS, ""},
{NULL, NULL, 0, NULL}
};
/* Initialize the module */
static struct PyModuleDef example = {
PyModuleDef_HEAD_INIT,
"example",
NULL,
-1,
ExampleMethods,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_example(void)
{
return PyModule_Create(&example);
}
有关编写 Python 扩展模块的更多信息,请参见 此处。如果 C 代码位于文件 example.c 中,则可以在将其添加到 meson.build 后编译它(参见 meson.build 文件中的示例),并按照其中的说明进行操作。完成后,运行脚本
import ctypes
import numpy as np
from scipy import ndimage, LowLevelCallable
from example import get_transform
shift = 0.5
user_data = ctypes.c_double(shift)
ptr = ctypes.cast(ctypes.pointer(user_data), ctypes.c_void_p)
callback = LowLevelCallable(get_transform(), ptr)
im = np.arange(12).reshape(4, 3).astype(np.float64)
print(ndimage.geometric_transform(im, callback))
产生的结果与原始 Python 脚本相同。
在 C 版本中,_transform 是回调函数,参数 output_coordinates 和 input_coordinates 的作用与 Python 版本中的作用相同,而 output_rank 和 input_rank 提供了 len(output_coordinates) 和 len(input_coordinates) 的等效值。变量 shift 通过 user_data 传递,而不是通过 extra_arguments。最后,C 回调函数返回一个整数状态,成功时为 1,否则为 0。
函数 py_transform 将回调函数包装在一个 PyCapsule 中。主要步骤是
初始化一个
PyCapsule。第一个参数是指向回调函数的指针。第二个参数是函数签名,它必须与
ndimage预期的签名完全匹配。上面,我们使用
scipy.LowLevelCallable来指定user_data,该数据是使用ctypes生成的。另一种方法是将数据提供给胶囊上下文,该上下文可以通过 PyCapsule_SetContext 设置,并在
scipy.LowLevelCallable中省略指定user_data。但是,在这种方法中,我们需要处理数据的分配/释放 - 在胶囊被销毁后释放数据可以通过在 PyCapsule_New 的第三个参数中指定一个非 NULL 回调函数来完成。
用于 ndimage 的 C 回调函数都遵循这种方案。下一节列出了接受 C 回调函数的 ndimage 函数,并给出了函数的原型。
下面,我们展示了使用 Numba、Cython、ctypes 或 cffi 而不是在 C 中编写包装代码来编写代码的替代方法。
Numba
Numba 提供了一种在 Python 中轻松编写低级函数的方法。我们可以使用 Numba 编写上面的代码,如下所示
# example.py
import numpy as np
import ctypes
from scipy import ndimage, LowLevelCallable
from numba import cfunc, types, carray
@cfunc(types.intc(types.CPointer(types.intp),
types.CPointer(types.double),
types.intc,
types.intc,
types.voidptr))
def transform(output_coordinates_ptr, input_coordinates_ptr,
output_rank, input_rank, user_data):
input_coordinates = carray(input_coordinates_ptr, (input_rank,))
output_coordinates = carray(output_coordinates_ptr, (output_rank,))
shift = carray(user_data, (1,), types.double)[0]
for i in range(input_rank):
input_coordinates[i] = output_coordinates[i] - shift
return 1
shift = 0.5
# Then call the function
user_data = ctypes.c_double(shift)
ptr = ctypes.cast(ctypes.pointer(user_data), ctypes.c_void_p)
callback = LowLevelCallable(transform.ctypes, ptr)
im = np.arange(12).reshape(4, 3).astype(np.float64)
print(ndimage.geometric_transform(im, callback))
Cython
与上面相同的代码可以在 Cython 中编写,代码量更少,如下所示
# example.pyx
from numpy cimport npy_intp as intp
cdef api int transform(intp *output_coordinates, double *input_coordinates,
int output_rank, int input_rank, void *user_data):
cdef intp i
cdef double shift = (<double *>user_data)[0]
for i in range(input_rank):
input_coordinates[i] = output_coordinates[i] - shift
return 1
# script.py
import ctypes
import numpy as np
from scipy import ndimage, LowLevelCallable
import example
shift = 0.5
user_data = ctypes.c_double(shift)
ptr = ctypes.cast(ctypes.pointer(user_data), ctypes.c_void_p)
callback = LowLevelCallable.from_cython(example, "transform", ptr)
im = np.arange(12).reshape(4, 3).astype(np.float64)
print(ndimage.geometric_transform(im, callback))
cffi
使用 cffi,您可以与驻留在共享库 (DLL) 中的 C 函数进行交互。首先,我们需要编写共享库,我们用 C 语言编写——此示例适用于 Linux/OSX
/*
example.c
Needs to be compiled with "gcc -std=c99 -shared -fPIC -o example.so example.c"
or similar
*/
#include <stdint.h>
int
_transform(intptr_t *output_coordinates, double *input_coordinates,
int output_rank, int input_rank, void *user_data)
{
int i;
double shift = *(double *)user_data;
for (i = 0; i < input_rank; i++) {
input_coordinates[i] = output_coordinates[i] - shift;
}
return 1;
}
调用库的 Python 代码是
import os
import numpy as np
from scipy import ndimage, LowLevelCallable
import cffi
# Construct the FFI object, and copypaste the function declaration
ffi = cffi.FFI()
ffi.cdef("""
int _transform(intptr_t *output_coordinates, double *input_coordinates,
int output_rank, int input_rank, void *user_data);
""")
# Open library
lib = ffi.dlopen(os.path.abspath("example.so"))
# Do the function call
user_data = ffi.new('double *', 0.5)
callback = LowLevelCallable(lib._transform, user_data)
im = np.arange(12).reshape(4, 3).astype(np.float64)
print(ndimage.geometric_transform(im, callback))
您可以在 cffi 文档中找到更多信息。
ctypes
使用 ctypes,C 代码和 so/DLL 的编译与上面的 cffi 相同。Python 代码不同
# script.py
import os
import ctypes
import numpy as np
from scipy import ndimage, LowLevelCallable
lib = ctypes.CDLL(os.path.abspath('example.so'))
shift = 0.5
user_data = ctypes.c_double(shift)
ptr = ctypes.cast(ctypes.pointer(user_data), ctypes.c_void_p)
# Ctypes has no built-in intptr type, so override the signature
# instead of trying to get it via ctypes
callback = LowLevelCallable(lib._transform, ptr,
"int _transform(intptr_t *, double *, int, int, void *)")
# Perform the call
im = np.arange(12).reshape(4, 3).astype(np.float64)
print(ndimage.geometric_transform(im, callback))
您可以在 ctypes 文档中找到更多信息。