dpss#
- scipy.signal.windows.dpss(M, NW, Kmax=None, sym=True, norm=None, return_ratios=False, *, xp=None, device=None)[source]#
计算离散长球面序列 (DPSS)。
DPSS(或 Slepian 序列)通常用于多锥度功率谱密度估计(参见 [1])。 序列中的第一个窗口可用于最大化主瓣中的能量集中,也称为 Slepian 窗口。
- 参数:
- Mint
窗口长度。
- NWfloat
对应于
2*NW = BW/f0 = BW*M*dt的标准化半带宽,其中dt取为 1。- Kmaxint | None, 可选
要返回的 DPSS 窗口数(阶数从
0到Kmax-1)。 如果为 None(默认),则仅返回一个形状为(M,)的窗口,而不是形状为(Kmax, M)的窗口数组。- symbool, 可选
当为 True(默认)时,生成一个对称窗口,用于滤波器设计。 当为 False 时,生成一个周期性窗口,用于频谱分析。
- norm{2, ‘approximate’, ‘subsample’} | None, 可选
如果为“approximate”或“subsample”,则窗口通过最大值进行归一化,并且使用
M**2/(M**2+NW)(“approximate”)或基于 FFT 的子采样移位(“subsample”)应用偶数长度窗口的校正比例因子,详见注意事项。 如果为 None,则当Kmax=None时使用“approximate”,否则使用 2(使用 l2 范数)。- return_ratiosbool, 可选
如果为 True,除了窗口之外,还返回集中度比率。
- xparray_namespace, 可选
可选的数组命名空间。 应与 array API 标准兼容,或由 array-api-compat 支持。 默认值:
numpy- device: any
输出的可选设备规范。 应与
xp中支持的设备规范之一匹配。
- 返回值:
- vndarray,形状 (Kmax, M) 或 (M,)
DPSS 窗口。 如果 Kmax 为 None,则为 1D。
- rndarray,形状 (Kmax,) 或 float, 可选
窗口的集中度比率。 仅当 return_ratios 计算结果为 True 时才返回。 如果 Kmax 为 None,则为 0D。
注意事项
此计算使用 [2] 中给出的三对角特征向量公式。
对于
Kmax=None的默认归一化,即窗口生成模式,仅使用 l-infinity 范数会创建一个具有两个 unity 值的窗口,这会在偶数阶和奇数阶之间产生轻微的归一化差异。 对于偶数样本数,M**2/float(M**2+NW)的近似校正用于抵消这种影响(参见下面的示例)。对于非常长的信号(例如,1e6 个元素),计算小几个数量级的窗口阶数并使用插值(例如,
scipy.interpolate.interp1d)以获得长度为 M 的锥度可能很有用,但这通常不会保留锥度之间的正交性。在 1.1 版本中添加。
参考文献
[1]Percival DB, Walden WT. Spectral Analysis for Physical Applications: Multitaper and Conventional Univariate Techniques. Cambridge University Press; 1993.
[2]Slepian, D. Prolate spheroidal wave functions, Fourier analysis, and uncertainty V: The discrete case. Bell System Technical Journal, Volume 57 (1978), 1371430.
[3]Kaiser, JF, Schafer RW. On the Use of the I0-Sinh Window for Spectrum Analysis. IEEE Transactions on Acoustics, Speech and Signal Processing. ASSP-28 (1): 105-107; 1980.
示例
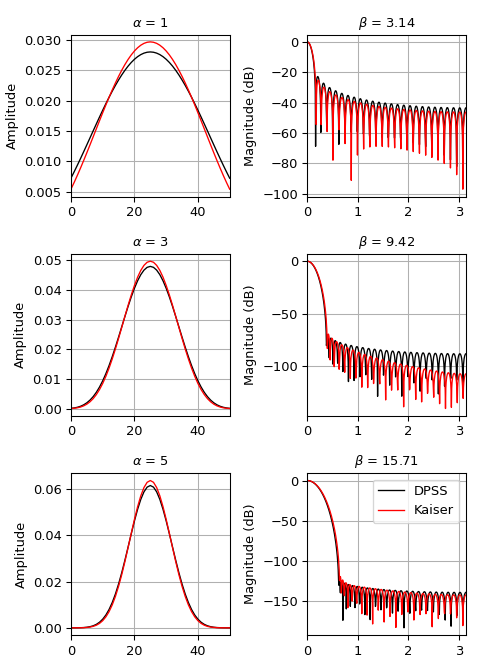
我们可以将窗口与
kaiser进行比较,后者是作为一种更容易计算的替代方案而发明的 [3](示例改编自 此处)>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from scipy.signal import windows, freqz >>> M = 51 >>> fig, axes = plt.subplots(3, 2, figsize=(5, 7)) >>> for ai, alpha in enumerate((1, 3, 5)): ... win_dpss = windows.dpss(M, alpha) ... beta = alpha*np.pi ... win_kaiser = windows.kaiser(M, beta) ... for win, c in ((win_dpss, 'k'), (win_kaiser, 'r')): ... win /= win.sum() ... axes[ai, 0].plot(win, color=c, lw=1.) ... axes[ai, 0].set(xlim=[0, M-1], title=rf'$\alpha$ = {alpha}', ... ylabel='Amplitude') ... w, h = freqz(win) ... axes[ai, 1].plot(w, 20 * np.log10(np.abs(h)), color=c, lw=1.) ... axes[ai, 1].set(xlim=[0, np.pi], ... title=rf'$\beta$ = {beta:0.2f}', ... ylabel='Magnitude (dB)') >>> for ax in axes.ravel(): ... ax.grid(True) >>> axes[2, 1].legend(['DPSS', 'Kaiser']) >>> fig.tight_layout() >>> plt.show()
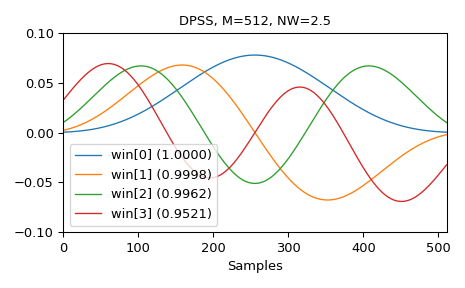
以下是前四个窗口的示例,以及它们的集中度比率
>>> M = 512 >>> NW = 2.5 >>> win, eigvals = windows.dpss(M, NW, 4, return_ratios=True) >>> fig, ax = plt.subplots(1) >>> ax.plot(win.T, linewidth=1.) >>> ax.set(xlim=[0, M-1], ylim=[-0.1, 0.1], xlabel='Samples', ... title=f'DPSS, {M:d}, {NW:0.1f}') >>> ax.legend([f'win[{ii}] ({ratio:0.4f})' ... for ii, ratio in enumerate(eigvals)]) >>> fig.tight_layout() >>> plt.show()
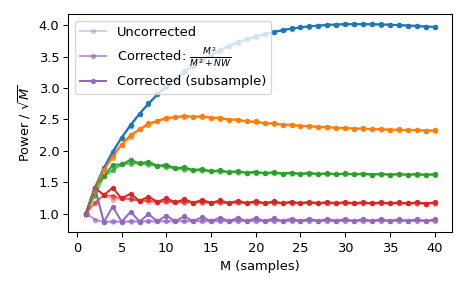
使用标准 \(l_{\infty}\) 范数会为偶数 M 生成两个 unity 值,但仅为奇数 M 生成一个 unity 值。 这会产生不均匀的窗口功率,可以通过近似校正
M**2/float(M**2+NW)来抵消,可以使用norm='approximate'(与norm=None相同,当Kmax=None时,这里就是这种情况)来选择。 或者,可以使用较慢的norm='subsample',它在频域中使用子样本移位 (FFT) 来计算校正>>> Ms = np.arange(1, 41) >>> factors = (50, 20, 10, 5, 2.0001) >>> energy = np.empty((3, len(Ms), len(factors))) >>> for mi, M in enumerate(Ms): ... for fi, factor in enumerate(factors): ... NW = M / float(factor) ... # Corrected using empirical approximation (default) ... win = windows.dpss(M, NW) ... energy[0, mi, fi] = np.sum(win ** 2) / np.sqrt(M) ... # Corrected using subsample shifting ... win = windows.dpss(M, NW, norm='subsample') ... energy[1, mi, fi] = np.sum(win ** 2) / np.sqrt(M) ... # Uncorrected (using l-infinity norm) ... win /= win.max() ... energy[2, mi, fi] = np.sum(win ** 2) / np.sqrt(M) >>> fig, ax = plt.subplots(1) >>> hs = ax.plot(Ms, energy[2], '-o', markersize=4, ... markeredgecolor='none') >>> leg = [hs[-1]] >>> for hi, hh in enumerate(hs): ... h1 = ax.plot(Ms, energy[0, :, hi], '-o', markersize=4, ... color=hh.get_color(), markeredgecolor='none', ... alpha=0.66) ... h2 = ax.plot(Ms, energy[1, :, hi], '-o', markersize=4, ... color=hh.get_color(), markeredgecolor='none', ... alpha=0.33) ... if hi == len(hs) - 1: ... leg.insert(0, h1[0]) ... leg.insert(0, h2[0]) >>> ax.set(xlabel='M (samples)', ylabel=r'Power / $\sqrt{M}$') >>> ax.legend(leg, ['Uncorrected', r'Corrected: $\frac{M^2}{M^2+NW}$', ... 'Corrected (subsample)']) >>> fig.tight_layout()