分段多项式和样条曲线#
一维插值例程 在上一节中讨论,通过构造某些分段多项式来工作:插值范围通过所谓的断点被分成多个区间,每个区间上有一个特定的多项式。这些多项式片段然后以预定义的平滑度在断点处匹配:三次样条曲线的二阶导数、单调插值的导数等等。
一个 k 次多项式可以被认为是 k+1 个单项式基元素的线性组合,\(1, x, x^2, \cdots, x^k\)。在某些应用中,考虑替代的(虽然在形式上等效的)基是很有用的。在 scipy.interpolate 中实现的两个流行基是 B 样条曲线 (BSpline) 和伯恩斯坦多项式 (BPoly)。B 样条曲线通常用于例如非参数回归问题,伯恩斯坦多项式用于构建贝塞尔曲线。
PPoly 对象以“通常的”幂基表示分段多项式。这是 CubicSpline 实例和单调插值的情况。通常,PPoly 对象可以表示任意阶的多项式,而不仅仅是三次多项式。对于数据数组 x,断点位于数据点处,系数数组 c 定义 k 次多项式,使得 c[i, j] 是段 x[j] 和 x[j+1] 之间 (x - x[j])**(k-i) 的系数。
BSpline 对象表示 B 样条函数 — B 样条基元素 的线性组合。这些对象可以直接实例化或使用 make_interp_spline 工厂函数从数据构建。
最后,伯恩斯坦多项式表示为 BPoly 类的实例。
所有这些类都实现了一个(大部分)类似的接口,PPoly 是功能最齐全的。我们接下来考虑这个接口的主要功能,并讨论分段多项式替代基的一些细节。
操作 PPoly 对象#
PPoly 对象具有用于构造导数和反导数、计算积分和求根的便捷方法。例如,我们对正弦函数进行表格化并找到其导数的根。
>>> import numpy as np
>>> from scipy.interpolate import CubicSpline
>>> x = np.linspace(0, 10, 71)
>>> y = np.sin(x)
>>> spl = CubicSpline(x, y)
现在,对样条曲线求导
>>> dspl = spl.derivative()
这里 dspl 是一个 PPoly 实例,它表示原始对象 spl 导数的多项式近似。在固定参数处评估 dspl 等效于使用 nu=1 参数评估原始样条曲线
>>> dspl(1.1), spl(1.1, nu=1)
(0.45361436, 0.45361436)
请注意,上面的第二种形式是在原地评估导数,而使用 dspl 对象,我们可以找到 spl 导数的零点
>>> dspl.roots() / np.pi
array([-0.45480801, 0.50000034, 1.50000099, 2.5000016 , 3.46249993])
这与 \(\cos(x) = \sin'(x)\) 的根 \(\pi/2 + \pi\,n\) 很吻合。请注意,默认情况下它计算了外推到插值区间 \(0 \leqslant x \leqslant 10\) 外部的根,并且外推结果(第一个和最后一个值)的精度要低得多。我们可以关闭外推并将求根限制在插值区间内
>>> dspl.roots(extrapolate=False) / np.pi
array([0.50000034, 1.50000099, 2.5000016])
事实上,root 方法是更通用的 solve 方法的特例,它为给定的常数 \(y\) 找到方程 \(f(x) = y\) 的解,其中 \(f(x)\) 是分段多项式
>>> dspl.solve(0.5, extrapolate=False) / np.pi
array([0.33332755, 1.66667195, 2.3333271])
这与预期的值 \(\pm\arccos(1/2) + 2\pi\,n\) 很吻合。
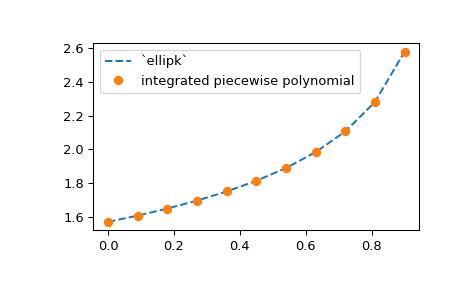
可以使用 .integrate 方法计算分段多项式的积分,该方法接受积分的下限和上限。作为一个例子,我们计算了完全椭圆积分 \(K(m) = \int_0^{\pi/2} [1 - m\sin^2 x]^{-1/2} dx\) 的近似值
>>> from scipy.special import ellipk
>>> m = 0.5
>>> ellipk(m)
1.8540746773013719
为此,我们将被积函数进行表格化并使用单调 PCHIP 插值法对其进行插值(我们也可以使用 CubicSpline)
>>> from scipy.interpolate import PchipInterpolator
>>> x = np.linspace(0, np.pi/2, 70)
>>> y = (1 - m*np.sin(x)**2)**(-1/2)
>>> spl = PchipInterpolator(x, y)
并积分
>>> spl.integrate(0, np.pi/2)
1.854074674965991
这确实接近于 scipy.special.ellipk 计算的值。
所有分段多项式都可以使用 N 维 y 值构造。如果 y.ndim > 1,它被理解为 1D y 值的堆栈,这些值沿着插值轴排列(默认值为 0)。后者通过 axis 参数指定,并且不变式是 len(x) == y.shape[axis]。作为一个例子,我们扩展了上面的椭圆积分示例,使用 NumPy 广播来计算一系列 m 值的近似值
>>> from scipy.interpolate import PchipInterpolator
>>> m = np.linspace(0, 0.9, 11)
>>> x = np.linspace(0, np.pi/2, 70)
>>> y = 1 / np.sqrt(1 - m[:, None]*np.sin(x)**2)
现在 y 数组的形状为 (11, 70),因此对于 m 的固定值,y 的值沿着 y 数组的第二轴排列。
>>> spl = PchipInterpolator(x, y, axis=1) # the default is axis=0
>>> import matplotlib.pyplot as plt
>>> plt.plot(m, spl.integrate(0, np.pi/2), '--')
>>> from scipy.special import ellipk
>>> plt.plot(m, ellipk(m), 'o')
>>> plt.legend(['`ellipk`', 'integrated piecewise polynomial'])
>>> plt.show()
B 样条曲线:节点和系数#
B 样条函数 — 例如,通过 make_interp_spline 调用从数据构建的函数 — 由所谓的节点和系数定义。
作为说明,让我们再次构建正弦函数的插值。节点作为t 属性,可从BSpline 实例获得
>>> x = np.linspace(0, 3/2, 7)
>>> y = np.sin(np.pi*x)
>>> from scipy.interpolate import make_interp_spline
>>> bspl = make_interp_spline(x, y, k=3)
>>> print(bspl.t)
[0. 0. 0. 0. 0.5 0.75 1. 1.5 1.5 1.5 1.5 ]
>>> print(x)
[ 0. 0.25 0.5 0.75 1. 1.25 1.5 ]
我们看到,默认情况下,节点向量是根据输入数组 x 构建的:首先,它被设置为\((k+1)\) -正则(它在开头和结尾附加了 k 个重复节点);然后,输入数组的第二个和倒数第二个点被删除——这就是所谓的非节点边界条件。
一般来说,度数为 k 的插值样条需要 len(t) - len(x) - k - 1 个边界条件。对于具有(k+1)-正则节点数组的三次样条,这意味着两个边界条件——或者从x 数组中删除两个值。可以使用make_interp_spline 的可选 bc_type 参数请求各种边界条件。
B 样条系数通过BSpline 对象的 c 属性访问
>>> len(bspl.c)
7
约定是,对于len(t) 个节点,有len(t) - k - 1 个系数。一些例程(见平滑样条部分)对 c 数组进行零填充,以使 len(c) == len(t)。这些额外的系数在评估时会被忽略。
我们强调,这些系数是在B 样条基 中给出的,而不是\(1, x, \cdots, x^k\) 的幂基。
B 样条基函数#
B 样条是分段多项式,表示为B 样条基函数的线性组合——这些基函数本身是普通单项式 \(x^m\) 的某些线性组合,其中 \(m=0, 1, \dots, k\)。
B 样条基通常比幂基在计算上更加稳定,并且对于包括插值、回归和曲线表示在内的各种应用很有用。主要特点是这些基函数是局部化的,并且在由节点数组定义的区间之外等于零。
具体来说,度数为 k(例如,对于三次样条,k=3)的 B 样条基函数由 \(k+2\) 个节点定义,并且在这些节点之外等于零。为了说明,在一个特定区间上绘制一系列非零基函数
>>> k = 3 # cubic splines
>>> t = [0., 1.4, 2., 3.1, 5.] # internal knots
>>> t = np.r_[[0]*k, t, [5]*k] # add boundary knots
>>> from scipy.interpolate import BSpline
>>> import matplotlib.pyplot as plt
>>> for j in [-2, -1, 0, 1, 2]:
... a, b = t[k+j], t[-k+j-1]
... xx = np.linspace(a, b, 101)
... bspl = BSpline.basis_element(t[k+j:-k+j])
... plt.plot(xx, bspl(xx), label=f'j = {j}')
>>> plt.legend(loc='best')
>>> plt.show()
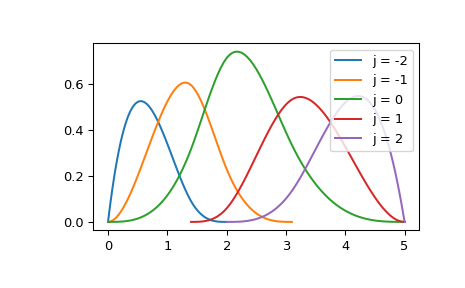
这里,BSpline.basis_element 本质上是构建仅具有单个非零系数的样条的简写。例如,上面示例中的 j=2 元素等效于
>>> c = np.zeros(t.size - k - 1)
>>> c[-2] = 1
>>> b = BSpline(t, c, k)
>>> np.allclose(b(xx), bspl(xx))
True
如果需要,可以使用 PPoly 对象的 PPoly.from_spline 方法将 B 样条转换为 PPoly 对象,该方法接收一个BSpline 实例并返回一个PPoly 实例。反向转换由BSpline.from_power_basis 方法执行。但是,最好避免基之间的转换,因为它会累积舍入误差。
B 样条基中的设计矩阵#
B 样条的一个常见应用是非参数回归。原因是 B 样条基函数的局部性质使得线性代数变得带状。这是因为在给定的评估点处最多有 \(k+1\) 个基函数非零,因此基于 B 样条构建的设计矩阵最多有 \(k+1\) 条对角线。
作为说明,我们考虑一个玩具示例。假设我们的数据是一维的,并且限制在区间 \([0, 6]\) 中。我们构建一个 4 正则节点向量,它对应于 7 个数据点和三次(k=3)样条
>>> t = [0., 0., 0., 0., 2., 3., 4., 6., 6., 6., 6.]
接下来,将“观测值”取为
>>> xnew = [1, 2, 3]
并以稀疏 CSR 格式构建设计矩阵
>>> from scipy.interpolate import BSpline
>>> mat = BSpline.design_matrix(xnew, t, k=3)
>>> mat
<Compressed Sparse Row sparse array of dtype 'float64'
with 12 stored elements and shape (3, 7)>
这里,设计矩阵的每一行对应于 xnew 数组中的一个值,并且一行最多有 k+1 = 4 个非零元素;第 j 行包含在 xnew[j] 处评估的基函数
>>> with np.printoptions(precision=3):
... print(mat.toarray())
[[0.125 0.514 0.319 0.042 0. 0. 0. ]
[0. 0.111 0.556 0.333 0. 0. 0. ]
[0. 0. 0.125 0.75 0.125 0. 0. ]]